Handling Errors
- how-to
Errors are inevitable. That’s why the SDK has very extensive error handling and retry capabilties which are focussed on one goal: keeping your application available as best as possible even in the face of (transient) failures.
Unfortunately, the SDK alone can’t make all the decisions needed since it lacks the understanding of your application domain. In most cases transparent retry is the best choice, but maybe sometimes you need to fail quickly and switch over to an alternate data source. On this page you will learn about basic and advanced error handling mechanisms, as well as the fundamentals that hold them all together.
Error Handling Fundamentals
The following fundamentals help you understand how the SDK makes retry decisions and how errors are surfaced. Later sections will cover how you can influence this behavior.
The Request Lifecycle
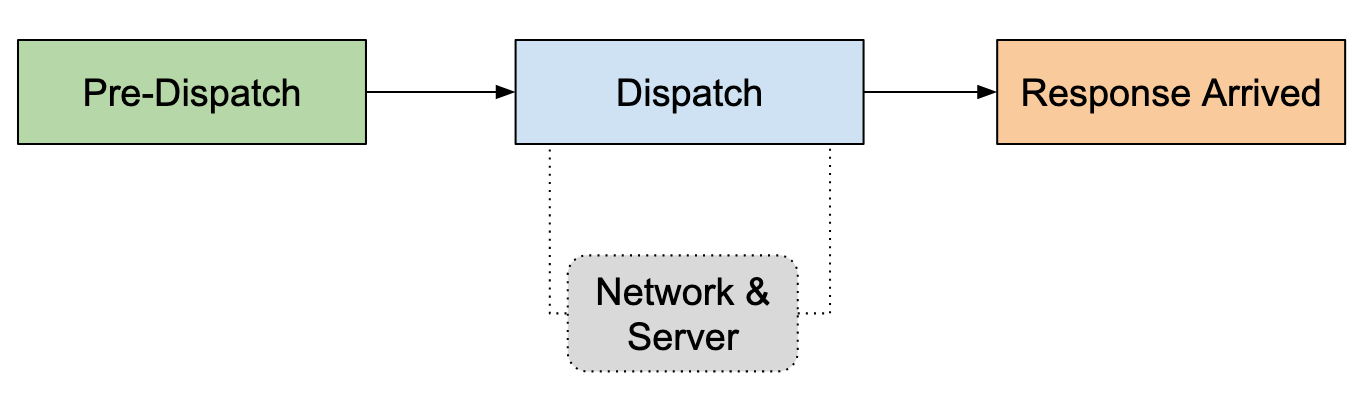
The following image shows the high-level phases during a request lifecycle:
-
Pre-Dispatch: This is the initial phase of the request lifecycle. The request is created and the SDK is trying to find the right socket/endpoint to dispatch the operation into.
-
Dispatch: The SDK puts the operation onto the network and waits for a response. This is a critical point in the lifecycle because the retryability depends on the idempotence of the request (discussed later).
-
Response Arrived: Once a response arrives from the server, the SDK decides what to do with it (in the best case, complete the operation successfully).
All the specifics are discussed below, but a broad categorization of exceptions can be outlined already:
-
If a response arrived and it indicates non-success and the SDK determines that it cannot be retried the operation will fail with an explicit exception. For example, if you perform an
insertoperation and the document already exists, the SDK will fail the operation with aDocumentExistsException. -
Failures in all other cases, especially during pre-dispatch and dispatch, will result in either a
TimeoutExceptionor aRequestCanceledException.
The Ubiquitous TimeoutException
The one exception that you are inevitably going to hit is the TimeoutException,
or more specifically its child implementations the UnambiguousTimeoutException and the AmbiguousTimeoutException.
It is important to establish a mindset that a timeout is never the cause of a problem, but always the symptom. A timeout is your friend, because otherwise your thread will just end up being blocked for a long time instead. A timeout gives you control over what should happen when it occurs, and it provides a safety net and last resort if the operation cannot be completed for whatever reason.
The SDK will raise an AmbiguousTimeoutException unless it can be sure that it did not cause any side effect on the server side (for example if an idempotent operation timed out, which is covered in the next section).
Most of the time it is enough to just handle the generic TimeoutException.
Since the timeout is never the cause, always the symptom, it is important to provide contextual information on what might have caused it in the first place.
In this newest generation of the SDK, we introduced the concept of an ErrorContext which helps with exactly that.
The ErrorContext is available as a method on the TimeoutException through the context() getter, but most importantly it is automatically attached to the exception output when printed in the logs.
Here is an example output of such a TimeoutException with the attached context:
Exception in thread "main" com.couchbase.client.core.error.UnambiguousTimeoutException: GetRequest, Reason: TIMEOUT {"cancelled":true,"completed":true,"coreId":"0x5b36b0db00000001","idempotent":true,"reason":"TIMEOUT","requestId":22,"requestType":"GetRequest","retried":14,"retryReasons":["ENDPOINT_NOT_AVAILABLE"],"service":{"bucket":"travel-sample","collection":"_default","documentId":"airline_10226","opaque":"0x24","scope":"_default","type":"kv"},"timeoutMs":2500,"timings":{"totalMicros":2509049}}
at com.couchbase.client.java.AsyncUtils.block(AsyncUtils.java:51)
// ... (rest of stack omitted) ...The full reference for the ErrorContext can be found at the bottom of the page, but just by looking at it we can observe the following information:
-
A
GetRequesttimed out after2500ms. -
The document in question had the ID
airline_10226and we used thetravel-samplebucket. -
It has been retried 14 times and the reason was always
ENDPOINT_NOT_AVAILABLE.
We’ll discuss retry reasons later in this document, but ENDPOINT_NOT_AVAILABLE signals that we could not send the operation over the socket because it was not connected/available.
Since we now know that the socket had issues, we can inspect the logs to see if we find anything related:
2020-10-16T10:28:48.717+0200 WARN endpoint:523 - [com.couchbase.endpoint][EndpointConnectionFailedEvent][2691us] Connect attempt 7 failed because of AnnotatedConnectException: finishConnect(..) failed: Connection refused: /127.0.0.1:11210 {"bucket":"travel-sample","channelId":"5B36B0DB00000001/000000006C7CDB48","circuitBreaker":"DISABLED","coreId":"0x5b36b0db00000001","local":"127.0.0.1:49895","remote":"127.0.0.1:11210","type":"KV"}
com.couchbase.client.core.deps.io.netty.channel.AbstractChannel$AnnotatedConnectException: finishConnect(..) failed: Connection refused: /127.0.0.1:11210
Caused by: java.net.ConnectException: finishConnect(..) failed: Connection refused
at com.couchbase.client.core.deps.io.netty.channel.unix.Errors.throwConnectException(Errors.java:124)
// ... (rest of stack omitted) ...Looks like we tried to connect to the server, but the connection got refused. Next step would be to triage the socket issue on the server side, but in this case it’s not needed since I just stopped the server for this experiment. Time to start it up again and jump to the next section!
Request Cancellations
Since we’ve covered timeouts already, the other remaining special exception is the RequestCanceledException.
It will be thrown in the following cases:
-
The
RetryStrategydetermined that theRetryReasonmust not be retried (covered later). -
Too many requests are being stuck waiting to be retried (signaling backpressure).
-
The SDK is already shut down when an operation is performed.
There are potentially other reasons as well, but where it originates is not as important as the information it conveys.
If you get a RequestCanceledException, it means the SDK is not able to further retry the operation and it is terminated before the timeout interval.
Transparently retrying should only be done if the RetryStrategy has been customized and you are sure that the retried operation hasn’t performed any side-effects on the server that can lead to data loss.
Most of the time the logs need to be inspected after the fact to figure out what went wrong.
To aid with debugging after the fact, the RequestCanceledException also contains an ErrorContext, very similar to what has been discussed in the timeout section above.
Idempotent vs. Non-Idempotent Requests
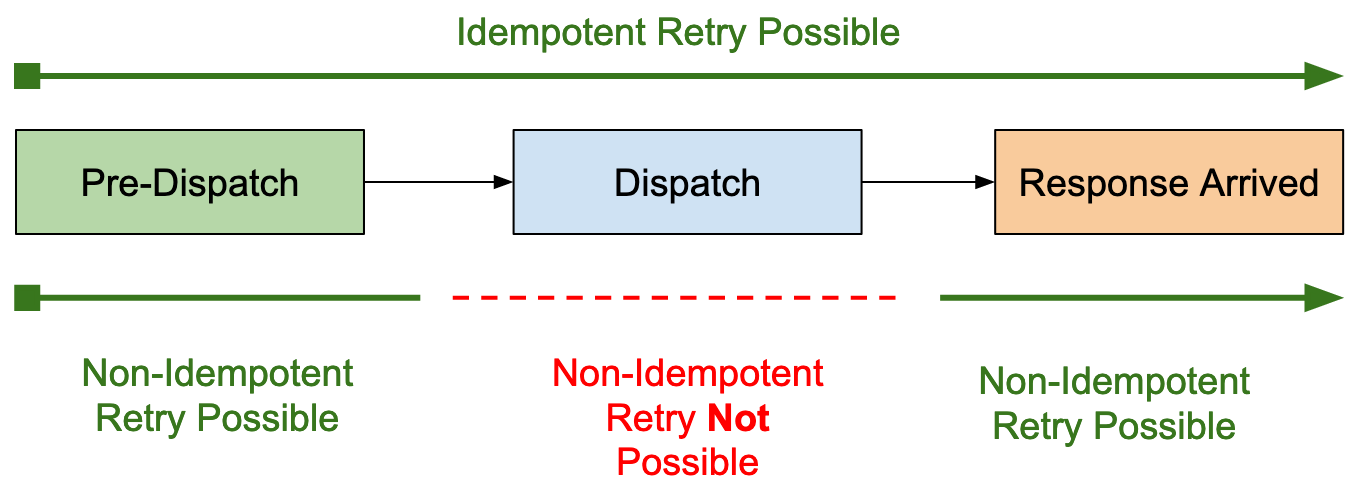
Operations flowing through the SDK are either idempotent or non-idempotent. If an operation is idempotent, it can be sent to the server multiple times without changing the result more than once.
This distinction is important when the SDK sends the operation to the server and the socket gets closed before it receives a response. If it is not idempotent the SDK cannot be sure if it caused a side-effect on the server side and needs to cancel it.
In this case, the application will receive a RequestCanceledException.
If it is idempotent though, the SDK will transparently retry the operation since it has a chance of succeeding eventually. Depending on the type of request, it might be able to send it to another node or the socket connection re-established before the operation times out.
If the operation needs to be retried before it is sent onto the network or after the SDK received a response, the idempotency doesn’t matter and other factors are taken into account. The following picture illustrates when idempotency is important in the request lifecycle:
The SDK is very conservative on which operations are considered idempotent, because it really wants to avoid accidential data loss. Imagine a situation where a mutating operation is applied twice by accident but another application server changed it in the meantime. That change is lost without a chance to potentially recover it.
The following operations are considered idempotent out of the box (aside from specific internal requests that are not covered):
-
Cluster:
search,ping,waitUntilReady. -
Bucket:
view,ping,waitUntilReady. -
Collection:
get,lookupIn,getAnyReplica,getAllReplicas,exists. -
Management commands that only retrieve information.
Both query and analyticsQuery commands are not in the list because the SDK does not inspect the statement string to check if you are actually performing a mutating operation or not.
If you are certain that you are only selecting data you can manually tell the client about it and benefit from idempotent retries:
QueryResult queryResult = cluster.query("SELECT * FROM `travel-sample`", queryOptions().readonly(true));
AnalyticsResult analyticsResult = cluster.analyticsQuery("SELECT * FROM `travel-sample`.inventory.airport",
analyticsOptions().readonly(true));The RetryStrategy and RetryReasons
The RetryStrategy decides whether or not a request should be retried based on the RetryReason.
By default, the SDK ships with a BestEffortRetryStrategy which, when faced with a retryable error, retries the request until it either succeeds or the timeout expires.
SDK 2 ships with a FailFastRetryStrategy which is intended to be used by an application.
SDK 3 also ships with one, but it is marked as @Internal.
We recommend extending and customizing the BestEffortRetryStrategy as described in Customizing the RetryStrategy.
|
The RetryReasons are good to look at (see the Reference section), because they give insight into why an operation got retried.
The ErrorContext described in the previous chapters exposes the reasons as a list, since it is certainly possible that a request gets retried more than once because of different reasons.
So a request might be retried on one occasion because the socket went down during dispatch,
and then on another because the response indicated a temporary failure.
See Customizing the RetryStrategy for more information on how to tailor the default behavior to your needs.
Exception Handling
In Java, all exceptions derive from a base CouchbaseException.
It acts as both a grouping mechanism and as a "catch all" possibility in case you need one.
It defines a ErrorContext context() getter, which in some exception cases might be null.
If it is available, it will be automatically included in the exception log output as mentioned above.
The CouchbaseException extends the RuntimeException, so no checked exceptions are defined throughout the SDK.
With the SDK retrying all transparently retryable exceptions already (unless you tune the RetryStrategy),
you are only left with terminal exceptions that are not retryable at all or where the SDK does not have enough context to decide on its own.
Handling Exceptions in the blocking API
Let’s consider one of the simpler examples - loading a document via Key/Value - to illustrate different try/catch strategies.
First, if you do not anticipate the document to not be present, it is likely that you are treating a DocumentNotFoundException as an error that is fatal.
In this case you can either propagate the CouchbaseException up your call stack, or rethrow it with a custom exception (here we define an arbitrary DatabaseException):
// This will raise a `CouchbaseException` and propagate it
GetResult result = collection.get("my-document-id");
// Rethrow with a custom exception type
try {
collection.get("my-document-id");
} catch (CouchbaseException ex) {
throw new DatabaseException("Couchbase lookup failed", ex);
}In a different case, a document not being present might be an indication that you need to create it. In this case you can catch it explicitly and handle it, while re-throwing all others:
try {
collection.get("my-document-id");
} catch (DocumentNotFoundException ex) {
createDocument("my-document-id");
} catch (CouchbaseException ex) {
throw new DatabaseException("Couchbase lookup failed", ex);
}Please refer to each individual method (javadoc) for more information about which exceptions are thrown on top of the TimeoutException and RequestCanceledException.
Now that we’ve covered falling back to another method or propagating the error, we also need to touch on retrying. As mentioned previously, the SDK will retry as much as it can, but in some cases it cannot know if an operation is retryable or not without the additional context you have as an application developer.
As an example, in your application you know that a particular document is only ever written by one app, so there is no harm in retrying an upsert operation in case of failure:
for (int i = 0; i < 10; i++) {
try {
collection.upsert("docid", JsonObject.create().put("my", "value"));
break;
} catch (TimeoutException ex) {
// propagate, since time budget's up
break;
} catch (CouchbaseException ex) {
System.err.println("Failed: " + ex + ", retrying.");
// don't break, so retry
}
}This code tries to upsert the document with a maximum of 10 attempts. While this code can be improved in various ways, it highlights an issue in general with blocking retries: usually you expect a single timeout for the operation which represents your upper limit. But in this case individual timeouts might add up to much more than a single operation timeout, since you are always issuing new timeouts.
There are ways to keep track of the remaining timeout and set it to a lower value when you perform the retry, but if you have sophisticated retry needs we recommend looking at reactive retry instead which is covered in the next section.
Reactive Exception Handling
Handling errors in the reactive API is very powerful, although a little more complex to understand at first. If you are new to reactive programming in general (or with the reactor library specifically), we recommend checking out The Reference Documentation first.
Similar to blocking code, if an operation fails there are usually three avenues to go down:
-
Bubble up the error to the caller.
-
Try a different method/API as a fallback.
-
Retry the original operation.
And these methods can also be combined to achieve staged functionality depending on the use case.
In reactor, errors are terminating signals which move through up the operator chain all the way to the subscriber unless they are handled specifically.
collection.reactive().get("this-doc-does-not-exist").subscribe(new Subscriber<GetResult>() {
@Override
public void onError(Throwable throwable) {
// This method will be called with a DocumentNotFoundException
}
@Override
public void onSubscribe(Subscription subscription) {
}
@Override
public void onNext(GetResult getResult) {
}
@Override
public void onComplete() {
}
});If .block() is called (instead of .subscribe()) at the end, the error will be thrown and can be caught with try/catch.
Usually though you either want to perform corrective action at some point or retry the operation.
The former can be achieved through the various reactor methods that start with onError*(…).
Do not confuse onError*(…) with doOnError(…).
The former actively changes the operator sequence while the latter should only be used to perform side effects (like logging) and does not alter the sequence at all.
|
The following example performs a get operation and switches to a fallback method called createDocumentReactive if the document does not exist.
Note that because get and upsert have different return types, we unify the API on the document content as a JsonObject which in this example will be returned to the user:
Mono<JsonObject> documentContent = collection.reactive().get("my-doc-id").map(GetResult::contentAsObject)
.onErrorResume(DocumentNotFoundException.class, e -> createDocumentReactive("my-doc-id"));If you want to perform a retry action, the reactor API allows you to do this very elegantly through the retryWhen(Retry retrySpec) API.
The retry spec is a builder-like API which allows you to define properties when, how and how often to retry.
The following code retries (only) a DocumentNotFoundException for a maximum of five times before giving up and propagating the error downstream.
collection.reactive().get("my-doc-id")
.retryWhen(Retry.max(5).filter(t -> t instanceof DocumentNotFoundException));There are many more options available on the Retry builder, please consult the official reactor documentation for more information.
We always recommend using the Retry class from the reactor.util.retry package.
Do not confuse it with the Retry class in the com.couchbase.client.core.retry.reactor package, which is deprecated and should not be used for this purpose.
|
Customizing the RetryStrategy
A custom RetryStrategy can be provided both at the environment (so it will take effect globally):
ClusterEnvironment environment = ClusterEnvironment.builder().retryStrategy(myCustomStrategy).build();Or it can be applied on a per-request basis:
collection.get("doc-id", getOptions().retryStrategy(myCustomStrategy));Both approaches are valid, although we recommend for most use cases to stick with the defaults and only to override it on a per requests basis.
If you find yourself overriding every request with the same different strategy, it can make sense to apply it locally in order to DRY it up a bit. There are no performance differences with both approaches, but make sure that even if you pass in a custom one on every request that you do not create a new one each time but rather share it across calls.
While it is possible to implement the RetryStrategy from scratch, we strongly recommend that instead the BestEffortRetryStrategy is extended and only the specifiy RetryReasons that need to be customized are handled.
In practice, it should look something like this:
class MyCustomRetryStrategy extends BestEffortRetryStrategy {
@Override
public CompletableFuture<RetryAction> shouldRetry(Request<? extends Response> request, RetryReason reason) {
// ---
// Custom Logic Here
// ---
// Do not forget to call super at the end as fallback!
return super.shouldRetry(request, reason);
}
}Importantly, do not omit the return super.shouldRetry(request, reason); as a fallback so that all other cases are handled for you.
Implementing a concrete example, there is a chance that you are using a CircuitBreaker configuration and want to fail-fast on an open circuit:
class MyCustomRetryStrategy2 extends BestEffortRetryStrategy {
@Override
public CompletableFuture<RetryAction> shouldRetry(Request<? extends Response> request, RetryReason reason) {
if (reason == RetryReason.ENDPOINT_CIRCUIT_OPEN) {
return CompletableFuture.completedFuture(RetryAction.noRetry());
}
return super.shouldRetry(request, reason);
}
}One important rule is that you should never block inside shouldRetry, since it is called on the hot code path and can considerably impact performance.
This is why the return type is enclosed in a CompletableFuture, indicating an async response type.
If you need to call out to third party systems over the network or the file system to make retry decisions, we recommend that you do this from a different thread and communicate via atomics, for example, so that the hot code path only needs to do cheap lookups.
The RetryAction indicates what should be done with the request: if you return a RetryAction.noRetry(), the orchestrator will cancel the request, resulting in a RequestCanceledException.
The other option is to call it through RetryAction withDuration(Duration duration), indicating the duration when the request should be retried next.
This allows you to customize not only if a request should be retried, but also when.
Not retrying operations is considered safe from a data-loss perspective.
If you are changing the retry strategy of individual requests keep the semantics discussed in Idempotent vs. Non-Idempotent Requests in mind.
You can check if a request is idempotent through the idempotent() getter, and also check if the RetryReason allows for non-idempotent retry through the allowsNonIdempotentRetry() getter.
If in doubt, check the implementation of the BestEffortRetryStrategy for guidance.
|
Reference
RetryReasons
The following table describes the user visible RetryReasons and indicate when they might occur.
The Non-Idempotent Retry gives an indication if non-idempotent operations also qualify for retry in this case.
Please also note that at this point in time the RetryReason enum is marked as volatile, so we do not provide stability guarantees for it.
| Name | Non-Idempotent Retry | Description |
|---|---|---|
NODE_NOT_AVAILABLE |
true |
At the time of dispatch there was no node available to dispatch to. |
SERVICE_NOT_AVAILABLE |
true |
At the time of dispatch there was no service available to dispatch to. |
ENDPOINT_NOT_AVAILABLE |
true |
At the time of dispatch there was no endpoint available to dispatch to. |
ENDPOINT_CIRCUIT_OPEN |
true |
The configured circuit breaker on the endpoint is open. |
ENDPOINT_NOT_WRITABLE |
true |
The endpoint is connected, but not writable at the moment. |
KV_ERROR_MAP_INDICATED |
true |
The Key/Value error map indicated a retry action on an unknown response code. |
KV_LOCKED |
true |
The server response indicates a locked document. |
KV_TEMPORARY_FAILURE |
true |
The server response indicates a temporary failure. |
KV_SYNC_WRITE_IN_PROGRESS |
true |
The server response indicates a sync write is in progress on the document. |
KV_SYNC_WRITE_RE_COMMIT_IN_PROGRESS |
true |
The server response indicates a sync write re-commit is in progress on the document. |
CHANNEL_CLOSED_WHILE_IN_FLIGHT |
false |
The underlying channel on the endpoint closed while this operation was still in-flight. |
BUCKET_NOT_AVAILABLE |
true |
The needed bucket for this document is currently not available in the SDK. |
BUCKET_OPEN_IN_PROGRESS |
true |
There is currently a bucket open action in progress. |
GLOBAL_CONFIG_LOAD_IN_PROGRESS |
true |
A concurrent global config loading is currently in progress. |
COLLECTION_MAP_REFRESH_IN_PROGRESS |
true |
A collection map refresh is currently in progress. |
VIEWS_TEMPORARY_FAILURE |
true |
The server view engine result indicates a temporary failure. |
SEARCH_TOO_MANY_REQUESTS |
true |
The server search engine result indicates it needs to handle too many requests. |
QUERY_PREPARED_STATEMENT_FAILURE |
true |
The server query engine indicates that the prepared statement failed and is retryable. |
QUERY_INDEX_NOT_FOUND |
true |
The server query engine indicates that the query index has not been found. |
ANALYTICS_TEMPORARY_FAILURE |
true |
The analytics query engine indicates that a temporary failure occured. |
ErrorContext
Depending on the operation the ErrorContext can be very different, and it also changes over time as we adjust settings to be more user-friendly and improve debugability.
The following table provides best-effort guidance explanation to most of the fields you’ll find in practice. Please note that we do not provide any stability guarantees on the names and values at this point (consider it volatile):
| Name | Description |
|---|---|
status |
The generic response status code which indicates sucess or why the operation failed (based on the server response). Correlates with the |
requestId |
A unique ID for each request which is assigned automatically. |
idempotent |
If the request is considered idempotent. |
requestType |
The type of request, derived from the class name. |
retried |
The number of times the request has been retried already. |
retryReasons |
Holds the different reasons why a request has been retried already (one entry per reason). |
completed |
If the request is already completed (might be success or failure). |
timeoutMs |
The timeout for this request, in milliseconds. |
cancelled |
Set to true if the operation is cancelled, why see |
reason |
If the request is cancelled, contains the |
clientContext |
Contains the clientContext set by the user in the request options. |
service |
Contains a map of service-specific properties (i.e. the opaque for key value, the statement for a SQL++ query etc) |
timings |
Contains information like how long encoding, dispatch, total time etc. took in microseconds. |
lastDispatchedTo |
If already sent to a node contains the host and port where it got sent to. |
lastDispatchedFrom |
If already sent to a node contains the host and port where it got sent from. |
lastChannelId |
If already sent to a node contains the channel ID that can be used to correlate with the server logs. |
Cloud Native Gateway
If you connect to the Kubernetes or OpenShift over our CloudNative Gateway, using the new couchbase2:// endpoints, there are a few changes in the error messages returned.
Some error codes are more generic — in cases where the client would not be expected to need to take specific action — but should cause no problem, unless you have written code looking at individual strings within the error messages.