Couchbase Operator Architecture
This section gives a high level overview of the Operator architecture.
Custom Resource Definitions
A custom resource definition (CRD) is a user defined type in Kubernetes. These allow us to create domain specific resources such as Couchbase clusters or Couchbase buckets that cannot be represented by other native types.
A CRD simply defines a type name within a group e.g. CouchbaseCluster in couchbase.com.
The Operator distributes CRDs with full JSON schema definitions attached to them.
This allows the Kubernetes API server to check the structure and types of incoming custom resources for validity.
Dynamic Admission Controller
The DAC allows custom resources to be interrogated before a resource is accepted and committed to etcd. It provides context specific validation logic for Couchbase clusters, that cannot be achieved through CRD JSON schema validation alone.
Another benefit is that Couchbase specific configuration errors are synchronously reported back to the user in real time, rather than errors appearing in the Operator log and going unnoticed.
For these reasons the DAC is a required component of the Operator and must be installed. The DAC is a standalone service and processes Couchbase cluster resources for the entire Kubernetes cluster, therefore only a single instance is required.
|
Dynamic Admission Controller Security Models
The recommended — and default — deployment model is to run a single instance of the DAC per Kubernetes cluster. The DAC is backward compatible with all previous CRD versions, therefore you only need to deploy the most recent version, regardless of the Operator versions running on the platform. The DAC may also be deployed at the namespace scope for more security conscious environments.
This limits the DAC so that it is only able to see Kubernetes resources within the namespace in which it is deployed, for example secrets.
With this security model, one instance of the DAC is required per namespace in which the Operator is deployed.
In the following DAC architecture section, when running the DAC namespaced, Regardless of chosen security model, the DAC will require cluster administrator privileges to deploy. The roles and role bindings require privilege escalation. Additionally the validating webhook affects the Kubernetes API, so must be installed by an administrator. |
|
Dynamic Admission Controller Security Rules
By default the DAC will check that Kubernetes secrets and storage classes exist and have not been misconfigured.
This is important because the validity of things like TLS certificates can be checked before attempting to create the cluster.
If the required permissions are too permissive for your environment then you can selectively remove them with the You may also use this opt-out feature to avoid the DAC rejecting configuration when the ordering of resource creation cannot be guaranteed, for example secrets are created after the Couchbase cluster resource. This is however not recommended as any configuration errors are reflected in resource status conditions and logs, not immediately reported to the console. |
Dynamic Admission Controller Architecture
The following is a simplified illustration of how the admission controller works:
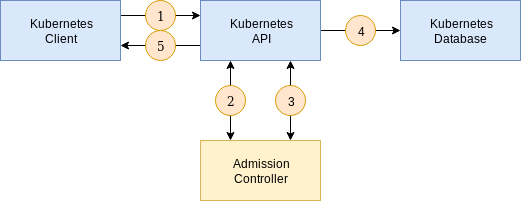
-
A client connects to the Kubernetes API and sends a request to create a resource. The resource specification is encoded as JSON.
-
The API forwards the JSON to the validating endpoint of the admission controller. A validating webhook is responsible for validating specification constraints above and beyond those offered by JSON schema validation provided by the custom resource definition. It may optionally choose to accept or reject the create request.
-
Once all admission checks have passed, the resource is persisted in the database (etcd).
-
The API responds to the client that the create request has been accepted.
If either of the admission checks in stages 2 and 3 respond that the resource is not acceptable, the API will go directly to stage 5 and return any errors returned by the admission controller.
Dynamic Admission Controller Resources
The admission controller is implemented as a simple web server.
The application layer protocol is HTTP over TLS.
The admission controller is deployed using Kubernetes native primitives, such as a Deployment, providing high availability and fault tolerance.
The DAC is stateless so more than one replica may be run for high-availability. The DAC is a statically compiled binary, so does not require an operating system image. The DAC does not require any elevated privileges and may be run as any user.
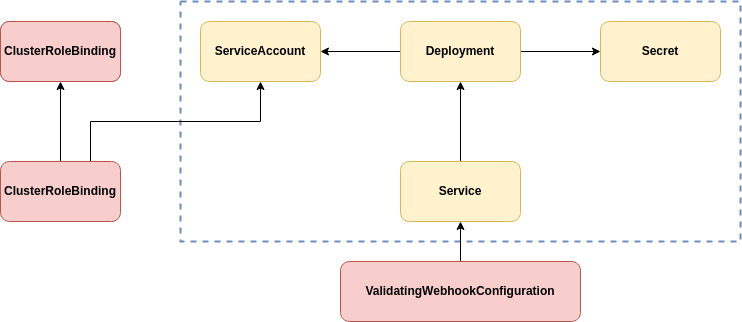
The dotted box in the diagram denotes namespaced resources. Resources highlighted in red must be created by an administrator who has permission to create cluster scoped resources, or those that grant privilege escalation.
The admission controller Deployment is associated with a ServiceAccount that grants the admission controller permissions to access other resources with a role.
Detailed role requirements are documented in the dynamic admission controller RBAC reference guide.
Access to resource types allows the admission controller to check that any resources, such as Secrets, are present for the Operator to access and use.
It also allows the admission controller to poll for existing CouchbaseCluster resources to check for invariance of certain specification attributes.
A Secret is used to provide TLS certificates to the DAC container.
A service endpoint is exposed with a Kubernetes Service resource that provides a stable DNS name, fault tolerance, and load balancing.
The service endpoint is finally bound to the Kubernetes API with a ValidatingWebhookConfiguration resource.
The webhook identifies the resource type and version, and the types of operation to respond to.
They also define the TLS CA certificate to use for validation of the service endpoint and the HTTP path to route requests to.
Operator
The Operator watches for events related to CouchbaseCluster resources.
The Operator reacts to creation events by provisioning new resources and initializing the Couchbase cluster.
During the lifetime of the Couchbase cluster the Operator continually compares the state of Kubernetes resources with what is requested in the CouchbaseCluster resource, reconciling as necessary to make reality match what was requested.
The Operator is also Couchbase Server aware, so can detect and fix faults that would not otherwise be visible to Kubernetes.
Polling the Kubernetes API continually to check for resource statuses is a costly operation. etcd is commonly shown to be a bottleneck. To prevent the Operator from causing unnecessary API traffic and database accesses it uses local caching of every resource type it manages. Subsequently it needs list and watch permissions on all managed resources. After the initial list operation, the API only informs the Operator of changes that have happened, reducing API traffic to the absolute minimum.
The Operator is designed to run in the same namespace as the Couchbase clusters it is managing. The Operator therefore needs one instance per namespace where Couchbase clusters are required to be provisioned. The Operator is a statically compiled binary, so does not require an operating system image. The Operator does not require any elevated privileges and may be run as any user.
|
Operator Security Models
The recommended deployment method for the Operator is a single instance per-namespace. This allows staged upgrades of the Operator, only affecting a subset of Couchbase clusters at any one time. The Operator may be deployed at the cluster scope, where a single Operator controls all Couchbase clusters on the platform.
While requiring less operational overhead, and upgrade of the Operator will affect all Couchbase clusters running on the platform, so use this deployment method with caution.
In the following operator resources section, |
Operator Resources
The Operator is a basic application that uses a Deployment to provide high-availability.
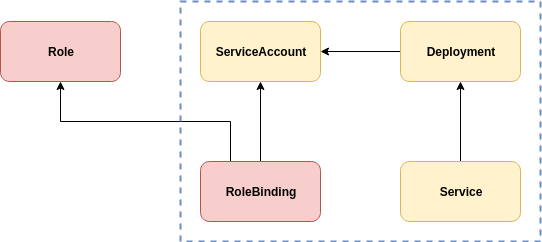
|
The dotted box in the diagram denotes namespaced resources. Resources highlighted in red must be created by an administrator who has permission to create cluster scoped resources, or those that grant privilege escalation. |
The Operator Deployment is associated with a ServiceAccount that grants the Operator permissions to discover, create, modify and delete resources required to manage a Couchbase cluster.
Detailed role requirements are documented in the Operator RBAC reference guide.
A Service is provided to allow access to Operator Prometheus metrics, if desired.
Reconciliation Order
The Operator takes a wide range of actions on the Couchbase cluster based on the CouchbaseCluster resource, this can sometimes result in unexpected behavior on the cluster if multiple changes are made to the CouchbaseCluster resource at once.
The order of reconciliation operations that the Operator performs is as follows:
Hibernation
Hibernating the cluster takes priority over everything else, if spec.hibernate is true then the Operator will hibernate the cluster without taking any further action.
Pre-requisite resources
The operator reconciles the requisite resources that are needed for the cluster to operate, this includes:
-
Kubernetes services to enable communication between Couchbase Pods
-
Kubernetes service to access the admin console (
couchbaseclusters.spec.networking.exposeAdminConsole) -
TLS Secrets
-
Logging Configuration Secret (
couchbaseclusters.spec.logging.server)
Cluster Creation
The Operator focuses on ensuring that a Couchbase Cluster is available by either recovering down pods or creating an initial Couchbase pod to start the cluster.
Node Reconciliation
The Operator makes topology changes to the cluster in the following order:
-
Waiting for nodes to warm-up
-
Handling down and failed nodes
-
Removing nodes from deleted server configurations
-
Volume expansions for persistent volumes
-
Upgrading Couchbase Server pods based on spec changes
-
Scaling down
-
Scaling up
-
Kubernetes services for Couchbase exposed features (
couchbaseclusters.spec.networking.exposedFeatures) -
Triggering Node Rebalancing
Post Topology Reconciliation
The Operator makes reconciles other cluster properties in the following order:
-
Cluster Networking
-
Mutable Pod Metadata (no topology changes)
-
Couchbase Server cluster settings
-
Buckets
-
Scopes and Collections
-
Bucket synchronization (
couchbaseclusters.spec.buckets.synchronize) -
XDCR connections (
couchbaseclusters.spec.xdcr) -
Kubernetes services for Couchbase exposed features (
couchbaseclusters.spec.networking.exposedFeatures) -
RBAC
-
Backups
-
Backup Restores
-
Cloud Native Gateway service
Couchbase Cluster
Couchbase clusters are create by the Operator responding to CouchbaseCluster resources.

All resources are linked to their parent CouchbaseCluster resource with owner references.
If a CouchbaseCluster is deleted this will cascade and delete all child resources.
ConfigMaps are used to persist state required per-cluster.
Pods are used to create Couchbase server instances.
PodDisruptionBudgets are used to control Kubernetes rolling-upgrades.
These prevent Kubernetes from draining nodes in a way that would result in data loss.
Services are used to establish DNS entries for communication with Couchbase server endpoints.
Per-node services can also be used to provide addressability to clients operating outside of the Kubernetes cluster.
Jobs and CronJobs are used to restore data to, and backup data periodically from, a Couchbase cluster.
PersistentVolumeClaims are used to provide high-performance disaster recovery in the event of a Couchbase server crash, accidental deletion or data center failure.
They are used as backing storage for Couchbase backups.
PersistentVolumeClaims related to Couchbase backups are not associated with the parent CouchbaseCluster, and are not deleted when the parent is.