Rebalance
Rebalance redistributes data, indexes, event processing, and query processing among available nodes.
Understanding Rebalance
When one or more nodes have been brought into a cluster (either by adding or joining), or have been taken out of a cluster (either through Removal or Failover), rebalance redistributes data, indexes, event processing, and query processing among available nodes. The cluster map is correspondingly updated and distributed to clients. The process occurs while the cluster continues to service requests for data.
See Cluster Manager, for information on the cluster map. See Manage Nodes and Clusters, for practical examples of using rebalance.
Rebalance Stages
Each rebalance proceeds in sequential stages. Each stage corresponds to a Couchbase Service, deployed on the cluster. Therefore, if all services have been deployed, there are seven stages in all — one each for the Data, Query, Index, Search, Eventing, Backup, and Analytics services. When all stages have been completed, the rebalance process itself is complete.
Rebalance and the Data Service
On rebalance, vBuckets are redistributed evenly among currently available Data Service nodes. After rebalance, operations are directed to active vBuckets in their updated locations. Rebalance does not interrupt applications' data-access. vBucket data-transfer occurs sequentially: therefore, if rebalance stops for any reason, it can be restarted from the point at which it was stopped.
Note the special case provided by Swap Rebalance, where the number of nodes coming into the cluster is equal to the number of nodes leaving the cluster, ensuring that data is only moved between these nodes.
If nodes have been removed such that the desired number of replicas can no longer be supported, rebalance provides as many replicas as possible. For example, if four Data Service nodes previously supported one bucket with three replicas, and the Data Service node-count is reduced to three, rebalance provides two replicas only. If and when the missing Data Service node is restored or replaced, rebalance will provide three replicas again.
See Intra-Cluster Replication, for information on how data is distributed across nodes.
Data-Service Rebalance Phases
During the Data Service rebalance stage, vBuckets are moved in phases. The phases — which differ, depending on whether the vBucket is an active or a replica vBucket — are described below.
Rebalance Phases for Replica vBuckets
The phases through which rebalance moves a replica vBucket are shown by the following illustration.
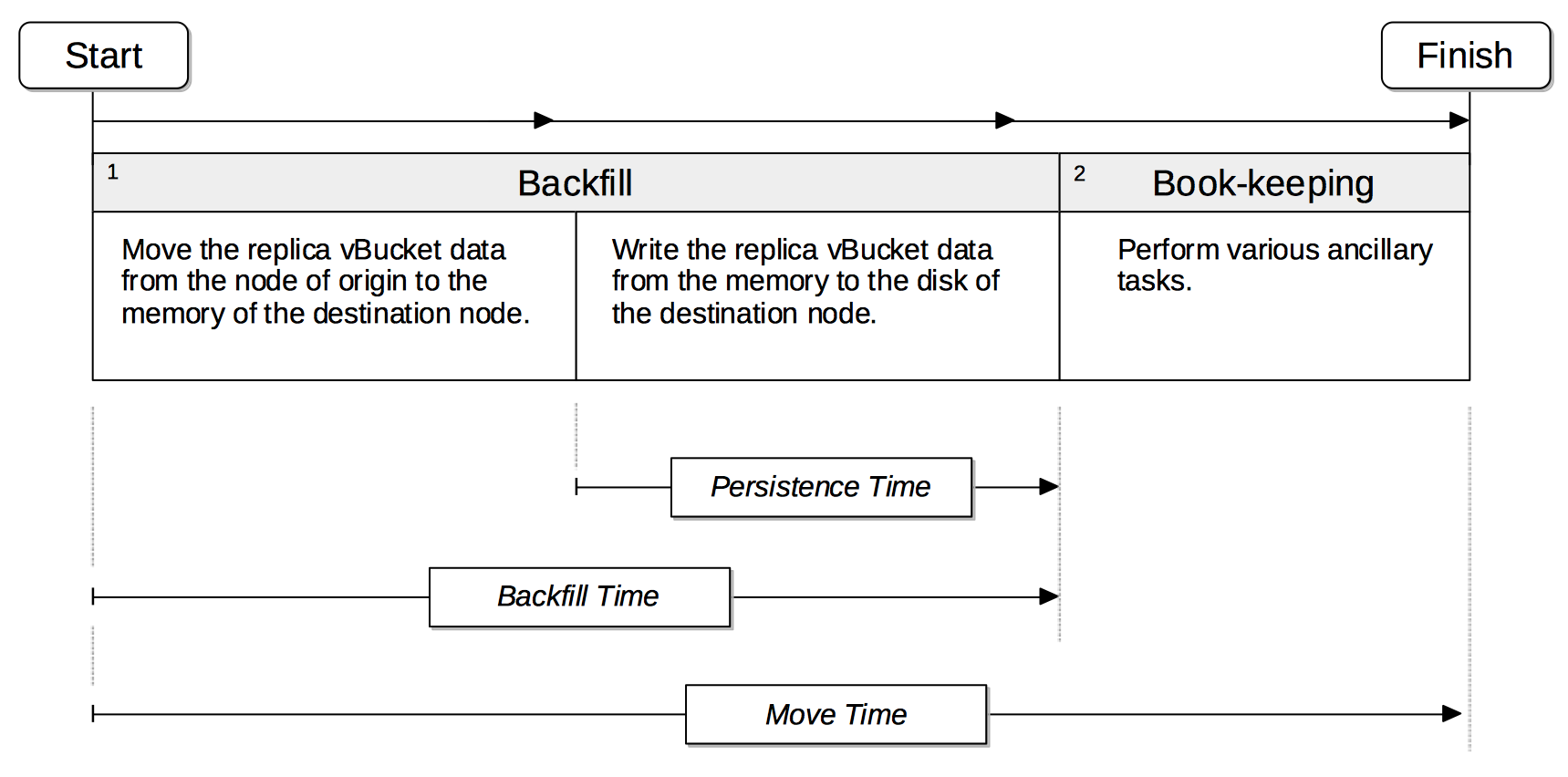
The move has two principal phases. Phase 1 is Backfill. Phase 2 is Book-keeping.
Phase 1, Backfill, itself consists of two subphases. The first subphase comprises the movement of the replica vBucket data from its node of origin to the memory of the destination node. The second subphase comprises the writing of the replica vBucket data from the memory to the disk of the destination node. The time required for this second subphase, which only applies to Couchbase Buckets, is termed Persistence Time. The time required for the entire Backfill process, including Persistence Time, is termed Backfill Time.
Phase 2, Book-keeping, comprises various ancillary tasks required for move-completion.
The total time required for the move is calculated by adding Backfill Time to the time required for Phase 2, Book-keeping; and is termed Move Time.
Rebalance Phases for Active vBuckets
The phases in which rebalance moves an active vBucket are shown by the following illustration.
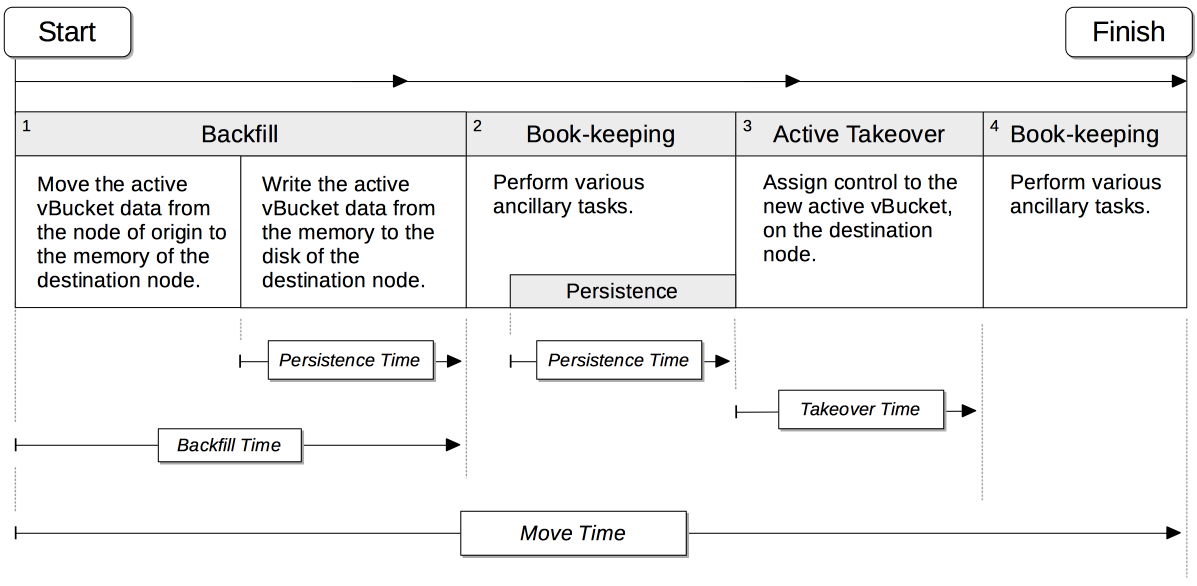
The move has four principal phases. Phase 1, Backfill, and Phase 2, Book-keeping, are identical to those required for replica vBuckets; except that the Book-keeping phase includes additional Persistence Time.
Phase 3, Active Takeover, comprises the operations required to establish the relocated vBucket as the new active copy. The time required for Phase 3 is termed Takeover Time.
Phase 4, Book-keeping, comprises a final set of ancillary tasks, required for move-completion.
The total time for the move is termed Move Time.
Limiting Concurrent vBucket Moves
Since vBucket moves are highly resource-intensive, Couchbase Server allows the concurrency of such moves to be limited: a setting is provided that determines the maximum number of concurrent vBucket moves permitted on any node.
The minimum value for the setting is 1, the maximum 64, the default 4.
A move counts toward this restriction only when in the backfill phase, as described above, in Data Service Rebalance Phases. The move may be of either an active or a replica vBucket. A node’s participation in the move may be as either a source or a target.
For example, if a node is at a given time the source for two moves in backfill phase, and is the target for two additional moves in backfill phase, and the setting stands at 4, the node may participate in the backfill phase of no additional moves, until at least one of its current moves has completed its backfill phase.
The setting may be established by means of the Couchbase Web Console, the Couchbase CLI, or the REST API.
A higher setting may improve rebalance performance, at the cost of higher resource consumption; in terms of CPU, memory, disk, and bandwidth. Conversely, a lower setting may degrade rebalance performance, while freeing up such resources. Note, however, that rebalance performance can be affected by many additional factors; and that in consequence, changing this parameter may not always have the expected effects. Note also that a higher setting, due to its additional consumption of resources, may degrade the performance of other systems, including the Data Service.
Accessing Rebalance Reports
Couchbase Server creates a report on every rebalance that occurs. The report contains a JSON document, which can be inspected in any browser or editor. The document provides summaries of the concluded rebalance activity, as well as details for each of the vBuckets affected: in consequence, the report may be of considerable length.
On conclusion of a rebalance, its report can be accessed in any of the following ways:
-
By means of Couchbase Web Console, as described in Add a Node and Rebalance.
-
By means of the REST API, as described in Getting Cluster Tasks.
-
By accessing the directory
/opt/couchbase/var/lib/couchbase/logs/rebalanceon any of the cluster nodes. A rebalance report is maintained here for (up to) the last five rebalances performed. Each report is provided as a*.jsonfile, whose name indicates the time at which the report was run — for example,rebalance_report_2020-03-17T11:10:17Z.json.
A complete account of the report-content is provided in the Rebalance Reference.
Rebalance and Other Services
Rebalance affects different services differently. The effects on services other than the Data Service are described below.
Index Service
The Index Service maintains a cluster-wide set of index definitions and metadata, which allows the redistribution of indexes and index replicas during a rebalance.
The rebalance process takes account of nodes' CPU and RAM utilization, and achieves the best resource-balance possible. Note that rebalance does not move indexes or replicas: instead, it rebuilds them in their new locations, using the latest data from the Data Service.
In Couchbase Server 7.0 and later, the index redistribution setting enables you to specify how Couchbase Server redistributes indexes on rebalance. The setting may be established by means of the Couchbase Web Console or the REST API.
The setting affects how indexes are redistributed in the following scenarios:
- Rebalance after an index node is added
-
If the setting is enabled, existing partitioned and non-partitioned indexes are placed optimally across all index nodes in the cluster, including any new index nodes being added. If the setting is disabled, only partitioned indexes are redistributed.
- Rebalance after a non-index node is added or removed
-
If the setting is enabled, partitioned and non-partitioned indexes are moved from heavily loaded nodes to nodes with free resources to achieve balanced distribution. If the setting is disabled, only partitioned indexes are redistributed.
- Rebalance during index server group repair
-
With multiple server groups, when a group failure leads to all replicas being placed in a single server group, if the setting is enabled, partitioned and non-partitioned indexes are redistributed to ensure high availability across the server groups after repair. If the setting is disabled, only partitioned indexes are redistributed.
The setting does not affect how indexes are redistributed in the following scenarios:
- Rebalance when an index node is removed
-
Partitioned and non-partitioned indexes are moved on rebalance from removed nodes to nodes that continue as part of the cluster. Indexes that reside on non-removed nodes are unaffected by rebalance.
- Rebalance when index nodes are added and removed
-
During a swap rebalance, indexes from ejected nodes are placed on the nodes being added.
If more index replicas exist than can be handled by the number of existing nodes, replicas are dropped: the numbers are automatically made up subsequently, if additional Index Service nodes are added to the cluster.
During rebalance, no index node is removed until index-building has completed on alternative nodes. This ensures uninterrupted access to indexes.
Smart Batching
When rebalance occurs, indexes are relocated and rebuilt in batches, so as to place a limit on the amount of work that is attempted concurrently — the default batch size being 3.
In Couchbase Server Version 7.1 and after, smart batching is used; so as to reduce further the time and resources required to move index metadata, and to rebuild indexes at their new locations during rebalance. Specifically, smart batching:
-
Increases rebalance performance by increasing pipeline parallelism, through starting the next batch while the prior batch is only partially completed.
-
Allows overall concurrency to be increased, through administrator-determined modifications of the batch size.
-
Optimizes the sharing of data streams, whereby index relocation occurs.
-
Repairs, prior to index relocation, index replicas lost due to node failure.
-
When appropriate, reassigns scheduled index-rebuilding from one batch to the next, in order to balance workloads.
Provided that at least one node in the cluster is running version 7.1+, most of the features of smart-batching apply to a cluster some of whose nodes are running an earlier version.
The default batch size of 3 can be changed by the Full Admin and Cluster Admin roles, by means of the REST API.
For information, see Modify Index Batch Size.
Search Service
The Search Service automatically partitions its indexes across all Search nodes in the cluster, ensuring optimal distribution, following rebalance.
To achieve this, in versions of Couchbase Server prior to 7.1, by default, partitions needing to be newly created were entirely built, on their newly assigned nodes. In 7.1+, by default, new partitions are instead created by the transfer of partition files from old nodes to new nodes: this significantly enhances performance. This is an Enterprise-only feature, which requires all Search Service nodes either to be running 7.1 or later; or to be running 7.0.2, with the feature explicitly switched on.
Community Edition clusters that are upgraded to Enterprise Edition 7.1+ thus gain this feature in its default setting. Community Edition clusters that are upgraded to Enterprise Edition 7.0.2 can have this feature switched on, subsequent to upgrade.
During file transfer, should an unresolvable error occur, file transfer is automatically abandoned, and partition build is used instead.
The file-transfer feature can be enabled and disabled by means of the REST API. See Rebalance Based on File Transfer.
Query Service
When a node is removed and rebalanced, the Query Service will allow existing queries and transactions to complete before shutting down, which may result in the rebalancing operation taking longer to complete.
The Query Service diagnostic log on the node(s) being removed will contain messages indicating how many transactions and queries are still running.
Any new connection attempts to nodes that are shutting down will receive error 1180 (E_SERVICE_SHUTTING_DOWN), and may receive error 1181 (E_SERVICE_SHUT_DOWN) in the brief period between the completion of the last statement or transaction and the service exiting.
Such rejected requests will have HTTP status code 503 (service unavailable) set.
Eventing Service
When an Eventing Service node has been added or removed, rebalance causes the mutation (vBucket processing ownership) and timer event processing workload to be redistributed among available Eventing Service nodes. The Eventing Service continues to process mutations both during and after rebalance. Checkpoint information ensures that no mutations are lost.
Analytics Service
The Analytics Service uses shadow data, which is a copy of all or some of the data maintained by the Data Service. By default, the shadow data is not replicated; however, it may be partitioned across all cluster nodes that run the Analytics Service. Starting with Couchbase Server 7.1, the shadow data and its partitions may be replicated up to 3 times. Each replica resides on an Analytics node: a given Analytics node can host a replica partition, or the active partition on which replicas are based.
If there are no Analytics replicas, and an Analytics node fails over, the Analytics Service stops working cluster-wide: ingestion of shadow data stops and no Analytics operations can be run. In this case:
-
If the Analytics node is recovered, the Analytics Service is resumed and ingestion of shadow data resumes from the point before the node failed over.
-
If the Analytics node is removed, the Analytics Service becomes active again after rebalance, but ingestion of shadow data must begin again from scratch.
If there are Analytics replicas, and an Analytics node fails over, the Analytics Service continues to work: one of the replicas is promoted to serve the shadow data that was stored on the failed over node. The Analytics Service only needs to rebuild any shadow data that isn’t already ingested from the Data Service, depending on the state of the promoted replica. In this case:
-
If the Analytics node is recovered, the shadow data on the recovered node is updated from the promoted replica, and it becomes the active partition again.
-
If the Analytics node is removed, the shadow data is redistributed among the remaining Analytics nodes in the cluster.
If no Analytics Service node has been removed or replaced, shadow data is not affected by rebalance. In consequence of rebalance, the Analytics Service receives an updated cluster map, and continues to work with the modified vBucket-topology.
Backup Service
A rebalance causes the scheduler for the Backup Service to stop running. This means that no new backup tasks are triggered until the rebalance has concluded; at which point, the scheduler restarts, and reconstructs the task schedule. Then, the triggering of Backup Service tasks is resumed.
Note that a rebalance has the effect of restarting the Backup Service whenever the service has previously been stopped, due to loss of its leader: for information, see Backup-Service Architecture.
Rebalance Failure-Handling
Rebalance failures can optionally be responded to automatically, with up to 3 retries. The number of seconds required to elapse between retries can also be configured. For information on configuration options, see General Settings. For information on failure-notifications, and options for cancelling rebalance-retries, see Automated Rebalance Failure Handling.