Search Service
The Search Service supports the creation of specially purposed indexes for Full Text Search.
Understanding Search
The Search Service provides extensive capabilities for search engine-like querying. These capabilities include, but are not limited to:
-
Language-aware searching; allowing users to search for, say, the word
beauties, and additionally obtain results forbeautyandbeautiful. -
Scoring of results, according to relevancy; allowing users to obtain result-sets that only contain documents awarded the highest scores. This keeps result-sets manageably small, even when the total number of documents returned is extremely large.
-
Fast indexes, which support a wide range of possible text-searches.
-
Geospatial queries, to return documents that contain a specified geographic location.
-
Range searches, including numeric range and date range queries.
-
Fuzzy matches, regular expression searches, and wildcard searches.
The indexes that the Search Service creates and uses are entirely separate from and different to those of the Index Service. However, if the Index and Query Services are also deployed on the cluster, the facilities of the Search Service can be called on by means of the N1QL language — which provides the principal interface to the Query and Index Services. See Accessing the Search Service with N1QL, below.
Search Service Architecture
The Search Service depends on the Data Service, as follows:
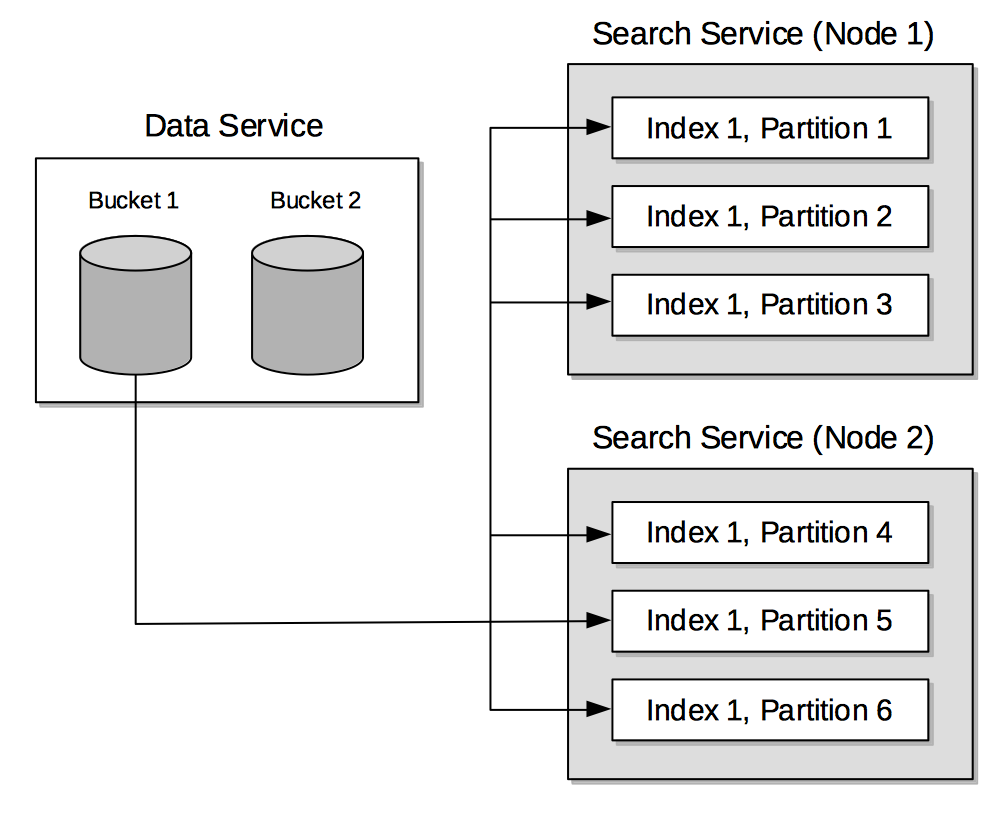
The shows the following:
-
The Data Service uses the DCP protocol to stream data-mutations as batches; from the producer to multiple consumers (vBuckets), instantiated across the search nodes.
-
When a search index is created by means of the Search Service, search-index data-handling for the vBuckets is divided equally among the established search-index partitions. For example, if the number of vBuckets is 120, and the number of search-index partitions chosen is 6, each search-index partition holds data for 20 vbuckets.
All available Search Service nodes in the cluster are individually searchable. When one particular Search Service node is chosen for a search request, it assumes the role of coordinator; and is thereby responsible for applying the search request to the other Search Service nodes, and for gathering and returning results. The following illustration depicts this scatter-gather execution of a search request:
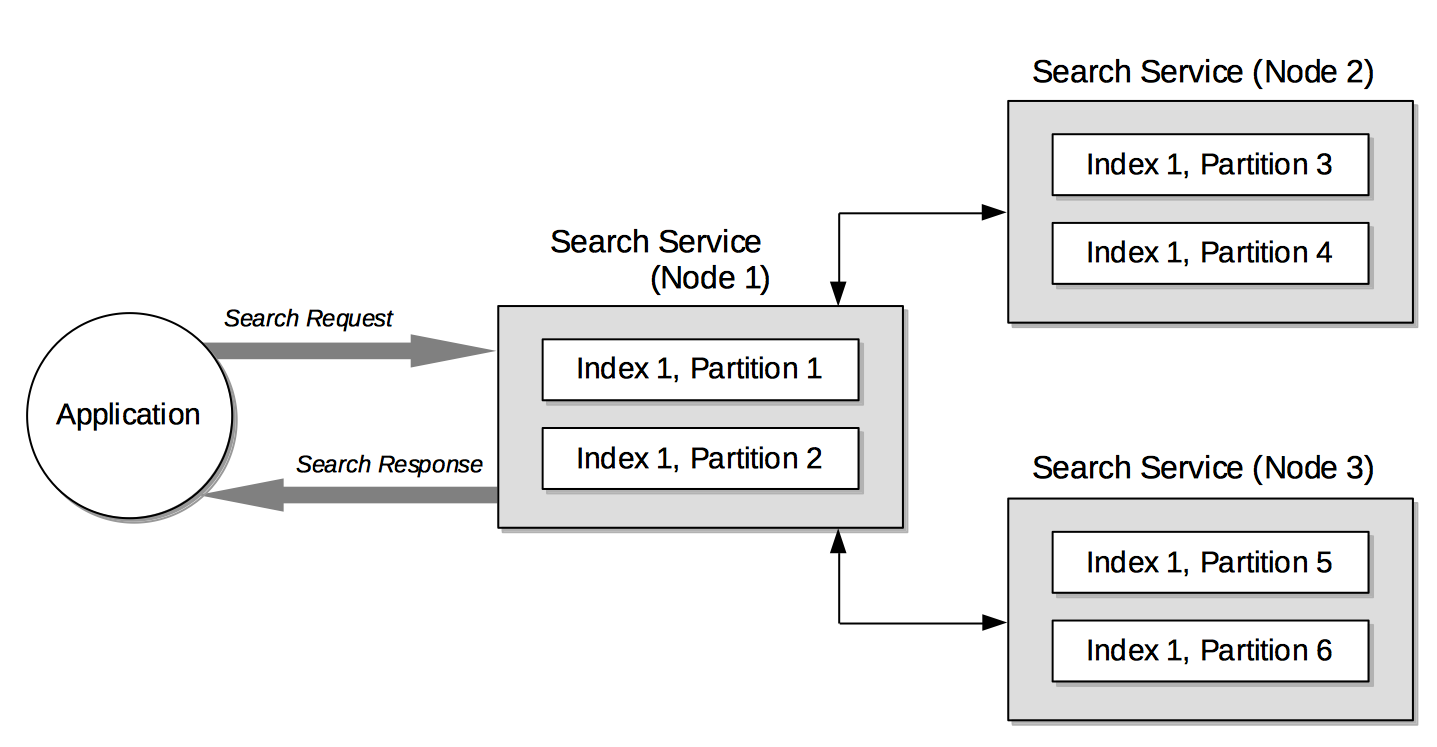
This illustration shows how:
-
The application makes a search request to a specific Search Service node (here, Node 1). This node assumes the role of coordinator.
-
The coordinator scatters the search request to all other search-index partitions (here, Node 2 and Node 3) in the cluster.
-
Once all the returned data is gathered, the coordinator applies filters as appropriate, and returns the final results to the user.
For extensive information on how to use the service, see Full Text Search: Fundamentals.
Accessing the Search Service with N1QL
The Search Service can be accessed by means of the search functions provided by the N1QL language — which provides the principal interface to the Query and Index Services. For detailed information, see Search Functions.
In Couchbase Server 6.6 Enterprise Edition and later, the Flex Index feature provides the ability for a N1QL query to use a Full Text Search index transparently with standard N1QL syntax. For detailed information, see Flex Indexes.
To use the Search Service in N1QL, the Query, Index, and Search Services must all be running on the cluster.