Cross Data Center Replication (XDCR)
Cross Data Center Replication (XDCR) allows data to be replicated across clusters that are potentially located in different data centers.
Introduction to XDCR
Cross Data Center Replication (XDCR) replicates data between a source bucket and a target bucket. The buckets may be located on different clusters, and in different data centers: this provides protection against data-center failure, and also provides high-performance data-access for globally distributed, mission-critical applications.
Note that Couchbase has modified the license restrictions to its Couchbase Server Community Edition package, for version 7.0 and higher: in consequence, XDCR is promoted to a commercial-only feature of Enterprise Edition. See Couchbase Modifies License of Free Community Edition Package, for more information on the license restrictions; and see XDCR and Community Edition, for information on how the new restrictions affect the experience of Community-Edition administrators.
Data from the source bucket is pushed to the target bucket by means of an XDCR agent, running on the source cluster, using the Database Change Protocol. Any bucket (Couchbase or Ephemeral) on any cluster can be specified as a source or a target for one or more XDCR definitions. Note, however, that if an Ephemeral bucket configured to eject data when its RAM-quota is exceeded is used as a source for XDCR, not all data written to the bucket is guaranteed to be replicated by XDCR. (See Buckets, for information on ejection.)
Cross Data Center Replication differs from intra-cluster replication in the following, principal ways:
-
As indicated by their respective names, intra-cluster replication replicates data across the nodes of a single cluster; while Cross Data Center Replication replicates data across multiple clusters, each potentially in a different data center.
-
Whereas intra-cluster replication is configured and performed with reference to only a single bucket (to which all active and replica vBuckets will correspond), XDCR requires two buckets to be administrator-specified, for a replication to occur: one is the bucket on the source cluster, which provides the data to be replicated; the other is the bucket on the target cluster, which receives the replicated data.
-
Whereas intra-cluster replication is configured at bucket-creation, XDCR is configured following the creation of both the source and target buckets.
The starting, stopping, and pausing of XDCR all occur independently of whatever intra-cluster replication is in progress on either the source or target cluster. While running, XDCR continuously propagates mutations from the source to the target bucket.
Tools and Procedures for Managing XDCR
Prior to XDCR management, source and target clusters should be appropriately prepared, as described in Prepare for XDCR. Then, XDCR is managed in three stages:
-
Define a reference to a remote cluster, which will be the target for Cross Data Center Replication. See Create a Reference.
-
Define and start a replication, which continuously transfers mutations from a specified source bucket to a specified target bucket. See Create a Replication.
-
Monitor the ongoing replication, pausing and resuming the replication if and when appropriate. See Monitor a Replication, Pause a Replication, and Resume a Replication.
Couchbase provides three options for managing these stages, which are by means of:
-
Couchbase Web Console, which provides a graphical user interface for interactive configuration and management of replications.
-
CLI, which provides commands and flags that allow replications to be managed from the command line.
-
REST API, which underlies both the Web Console and CLI, and can be expressed either as a
curlcommand on the command line, or within a program or script.
For procedures that cover all main XDCR management tasks, performed with all three of the principal tools, see XDCR Management Overview.
XDCR Direction and Topology
XDCR allows replication to occur between source and target clusters in either of the following ways:
-
Unidirectionally: The data contained in a specified source bucket is replicated to a specified target bucket. Although the replicated data on the source could be used for the routine serving of data, it is in fact intended principally as a backup, to support disaster recovery.
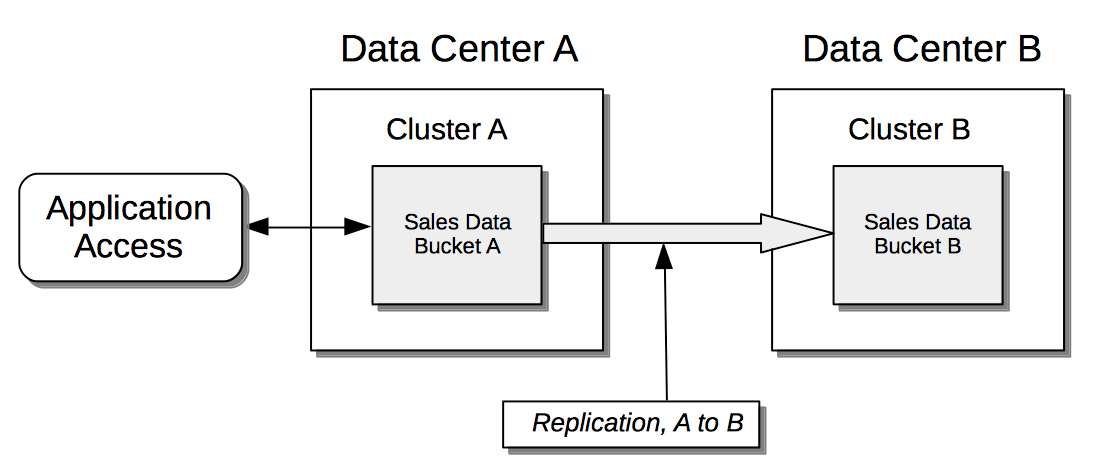
-
Bidirectionally: The data contained in a specified source bucket is replicated to a specified target bucket; and the data contained in the target bucket is, in turn, replicated back to the source bucket. This allows both buckets to be used for the serving of data, which may provide faster data-access for users and applications in remote geographies.
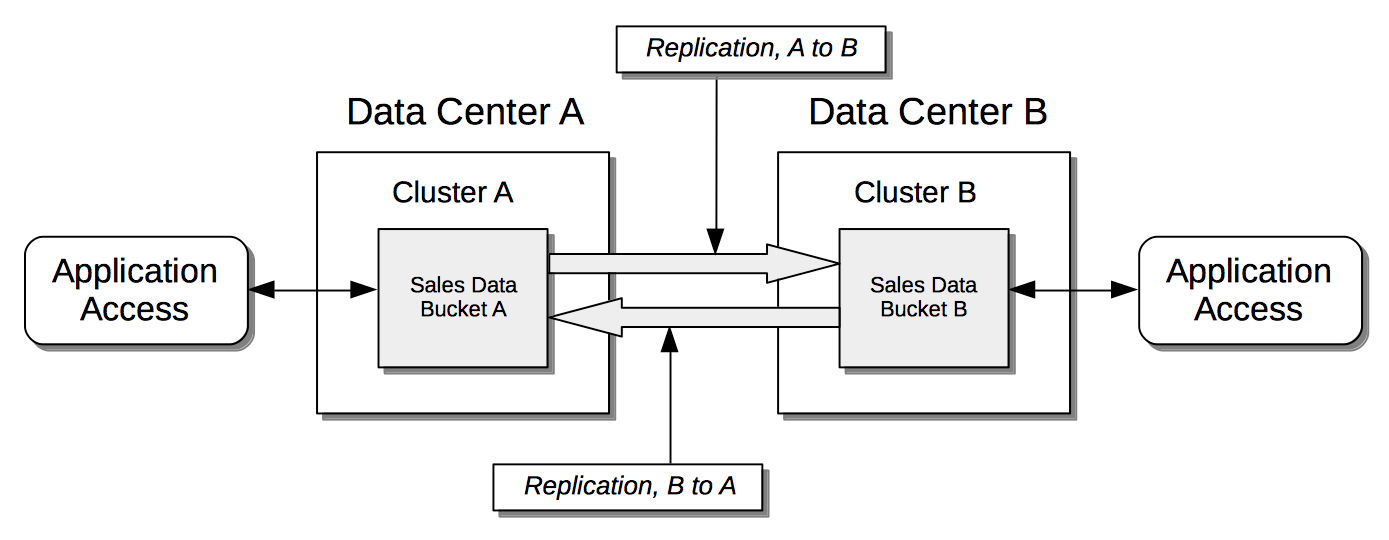
Note that XDCR provides only a single basic mechanism from which replications are built: this is the unidirectional replication. A bidirectional topology is created by implementing two unidirectional replications, in opposite directions, between two clusters; such that a bucket on each cluster functions as both source and target.
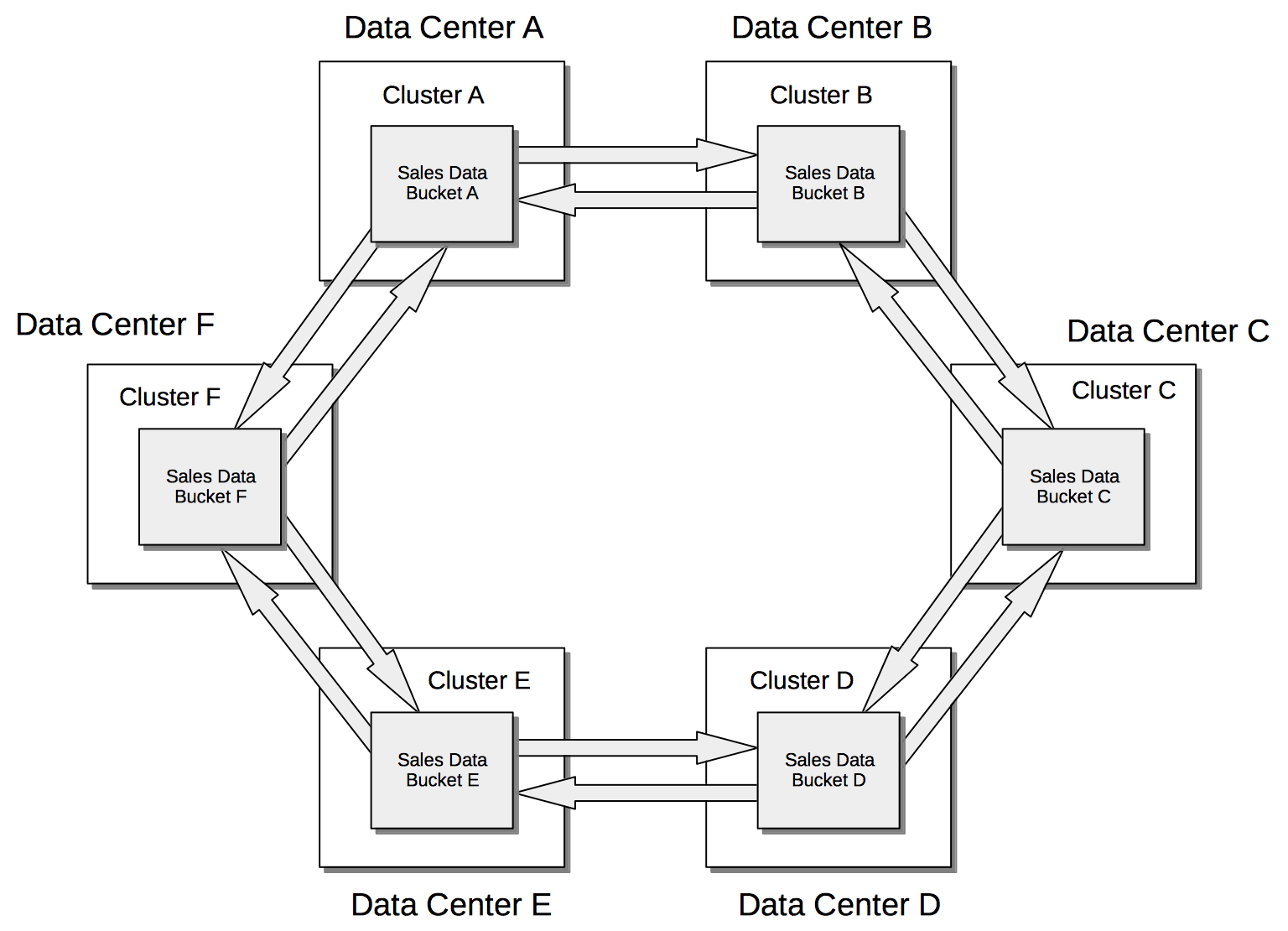
Used in different combinations, unidirectional and bidirectional replication can support complex topologies; an example being the ring topology, where multiple clusters each connect to exactly two peers, so that a complete ring of connections is formed:
XDCR Advanced Filtering
Filtering Expressions can be used in XDCR replications. Each is a regular expression that is applied to the document keys on the source cluster: those document keys returned by the filtering process correspond to the documents that will be replicated to the target. For information, See XDCR Advanced Filtering.
Optionally, deletion filters can be applied to a replication: these control whether the deletion of a document at source causes deletion of a replica that has been created. Each filter covers a specific deletion-context. For a description of the individual deletion filters, see Deletion Filters. For an explanation of the relationship between deletion filters and filters formed with regular and other filtering expressions, see Using Deletion Filters.
XDCR Payloads
XDCR only replicates data: it does not replicate views or indexes. Views and indexes can only be replicated manually, or by administrator-provided automation: when the definitions are pushed to the target server, the views and indexes are regenerated there.
When encountered on the source cluster, non-UTF-8 encoded document IDs are automatically filtered out of replication: they are therefore not transferred to the target cluster.
For each such ID, the warning output xdcr_error.* is written to the log files of the source cluster.
XDCR Using Scopes and Collections
XDCR supports scopes and collections, which are provided with Couchbase Server Version 7.0 and after. Scopes and collections are supported in the following ways:
-
Replication based on implicit mapping. Whenever a keyspace (i.e. a reference to the location of a collection within its scope, provided as scope-name.collection-name) is identical on source and target clusters, XDCR replicates documents from the source collection to the target collection automatically, when the respective buckets are specified as source and target.
-
Replicaton based on explicit mapping. The data in any source collection can be replicated to any target collection, as specified by the administrator.
-
Migration. Data in the default collection of a source bucket can be replicated to an administrator-defined collection in the target bucket.
Be aware that performing data migration may result in data loss when using XDCR filters to delete data.
If you are running filters that remove data, be sure to read Configuring Deletion Filters to Prevent Data-Loss before attempting a migration.
In each case, filtering can be applied.
The source-bucket may be:
-
A bucket on a 7.0+ cluster, housing its data in administrator-defined collections. Thus, data can be replicated (optionally using XDCR Advancing Filtering), from one collection to another within the same bucket; or from a collection in one bucket to a collection in another bucket.
-
A bucket on a 7.0+ cluster, housing its data in the
_defaultcollection, within the_defaultscope (this being the default initial residence for all data in a bucket whose cluster has been upgraded from a pre-7.0 Couchbase Server version to a 7.0+ version). Thus, XDCR can subsequently be used to redistribute the data into administrator-defined collections, either within the same or within different buckets (again, optionally using XDCR Advancing Filtering).
Note that whereas implicit replication is available in both Couchbase Server Enterprise and Community Edition, explicit replication and migration are available only in Couchbase Server Enterprise Edition.
For an introduction to scopes and collections, see Scopes and Collections. For more information on how XDCR works with scopes and collections, see XDCR with Scopes and Collections. Examples of collections-based XDCR are provided in Replicate Using Scopes and Collections.
XDCR Process
When a replication is created, it is stored internally as a replication specification. When the replication is started, XDCR reads the specification and creates a pipeline, which requests data from the source bucket, and examines every document in turn, to determine whether it is a candidate for replication to the target bucket. A document is only replicated if both of the following requirements are satisfied:
-
The document meets whatever filtering criteria may have been configured. For information, See XDCR Advanced Filtering.
-
The source collection within which the document resides can be mapped to a collection within the target bucket. For information, see XDCR with Scopes and Collections.
If, for a given document, one or both criteria are not satisfied, the document is dropped from the XDCR replication pipeline, and therefore not replicated: however, the attempted replication of other documents is continued.
Subsequent to the initial attempt to replicate all documents in the source bucket, documents are only replicated from the source bucket to the target bucket in the following circumstances:
-
The document is mutated: which is to say, it is created, modified, deleted, or expired.
Replication of a deleted or expired document means that the document will be correspondingly deleted or expired on the target. Note that this is the default behavior; although options are provided for not replicating deletion or expiration mutations — so that the replicated documents are not removed. See the reference information for the CLI xdcr-replicate command.
-
On the target bucket, a collection is created that allows a new mapping to occur between a source collection and the new target collection. For information, see Target-Collection Removal and Addition.
-
The current replication is restarted, following the editing of filtering criteria. For more information, see Filter-Expression Editing.
-
The current replication is deleted, and a new replication is created and started.
XDCR Priority
When throughput is high, multiple simultaneous XDCR replications are likely to compete with one another for system resources. In particular, when a replication starts, its initial process may be highly consumptive of memory and bandwidth, since all documents in the source bucket are being handled.
To manage system resources in these circumstances, each replication can be assigned a priority of High, Medium, or Low:
-
High. No resource constraints are applied to the replication. This is the default setting.
-
Medium. Resource constraints are applied to the replication while its initial process is underway, if the replication is in competition with one or more High priority replications. Subsequently, it is treated as a High priority replication.
-
Low. Resource constraints are applied to the replication whenever it is in competition with one or more High priority replications.
XDCR Conflict Resolution
In some cases, especially when bidirectionally replicated data is being modified by applications in different locations, conflicts may arise: meaning that the data of one or more documents has been differently modified more or less simultaneously, requiring resolution. XDCR provides options for conflict resolution, based on either sequence number or timestamp, whereby conflicted data can be saved consistently on source and target. For more information, See XDCR Conflict Resolution.
XDCR-Based Data Recovery
In the event of data-loss, the cbrecovery tool can be used to restore data. The tool accesses remotely replicated buckets, previously created with XDCR, and copies appropriate subsets of their data back onto the original source cluster.
By means of intra-cluster replication, Couchbase Server allows one or more replicas to be created for each vBucket on the cluster. This helps to ensure continued data-availability in the event of node-failure.
However, if multiple nodes within a single cluster fail simultaneously, one or more active vBuckets and all their replicas may be affected; meaning that lost data cannot be recovered locally.
In such cases, provided that a bucket affected by such failure has already been established as a source bucket for XDCR, the lost data may be retrieved from the bucket defined on the remote server as the corresponding replication-target. This retrieval is achieved from the command-line, by means of the Couchbase cbrecovery tool.
For a sample step-by-step procedure, see Recover Data with XDCR.
XDCR Security
XDCR configuration requires that the administrator provide a username and password appropriate for access to the target cluster. When replication occurs, the password is automatically supplied, along with the data. By default, XDCR transmits both password and data in non-secure form. Optionally however, a secure connection can be enabled between clusters, in order to secure either password alone, or both password and data. The password received by the destination cluster can be authenticated either locally or externally, as described in Authentication.
A secure XDCR connection is enabled either by SCRAM-SHA or by TLS — depending on the administrator-specified connection-type, and the server-version of the destination cluster. Use of TLS involves certificate management: for information on preparing and using certificates, see Manage Certificates.
Two administrator-specified connection-types are possible:
-
Half Secure: Secures the specified password only: it does not secure data. The password is secured by hashing with SCRAM-SHA, when the destination cluster is running Couchbase Enterprise Server 5.5 or later; and by TLS encryption, when the destination cluster is running a pre-5.5 Couchbase Enterprise Server. The root certificate of the destination cluster must be provided, for a successful TLS connection to be achieved.
Before attempting to enable half-secure replications, see the important information provided in SCRAM SHA and XDCR.
-
Full Secure: Handles both authentication and data-transfer via TLS.
For step-by-step procedures, see Secure a Replication.
XDCR Advanced Settings
The performance of XDCR can be fine-tuned, by means of configuration-settings, specified when a replication is defined. These settings modify compression, source and target nozzles (worker threads), checkpoints, counts, sizes, network usage limits, and more. For detailed information, see XDCR Advanced Settings.
XDCR Bucket Flush
The flush operation deletes data on a local bucket: this operation is disabled if the bucket is currently the source for an ongoing replication. If the target bucket is flushed during replication, the bucket becomes temporarily inaccessible, and replication is suspended.
If either a source or a target bucket needs to be flushed after a replication has been started, the replication must be deleted, the bucket flushed, and the replication then recreated.
XDCR and Expiration
Buckets, collections, and documents have a TTL setting, which determines the maximum expiration times of individual items. This is explained in detail in Expiration. For specific information on how TTL is affected by XDCR, see the section Expiration and XDCR.
Monitoring XDCR
Couchbase Server provides the ability to monitor ongoing XDCR replications, by means of the Couchbase Web Console. Detailed information is provided in Monitor a Replication.
XDCR Compatibility
The following table indicates XDCR compatibility between different versions of Couchbase Enterprise Server, used for source and target clusters.
Enterprise Server Version |
7.2.0 |
7.1.4, 7.1.3, 7.1.2, 7.1.1 |
7.1.0 |
7.0.x |
6.6.x |
7.2.0 |
✓ |
✓ |
✓ |
✓ |
✓ |
7.1.4, 7.1.3, 7.1.2, 7.1.1 |
✓ |
✓ |
✓ |
✓ |
✓ |
7.1.0 |
✓ |
✓ |
✓ |
✓ |
❌ |
7.0.x |
✓ |
✓ |
✓ |
✓ |
✓ |
6.6.x |
✓ |
✓ |
❌ |
✓ |
✓ |