Aggregate Functions
- Capella Operational
- reference
Aggregate functions take multiple values from documents, perform calculations, and return a single value as the result. The function names are case insensitive.
You can only use aggregate functions in SELECT, LETTING, HAVING, and ORDER BY clauses.
When using an aggregate function in a query, the query operates as an aggregate query.
In Couchbase Capella, aggregate functions can also be used as window functions when they are used with a window specification, which is introduced by the OVER keyword.
In Couchbase Server 7.0 and later, window functions (and aggregate functions used as window functions) may specify their own inline window definitions, or they may refer to a named window defined by the WINDOW clause elsewhere in the query. By defining a named window with the WINDOW clause, you can reuse the window definition across several functions in the query, potentially making the query easier to write and maintain.
Syntax
This section describes the generic syntax of aggregate functions. Refer to sections below for details of individual aggregate functions.
aggregate-function ::= aggregate-function-name '(' ( aggregate-quantifier? expr |
( path '.' )? '*' ) ')' filter-clause? over-clause?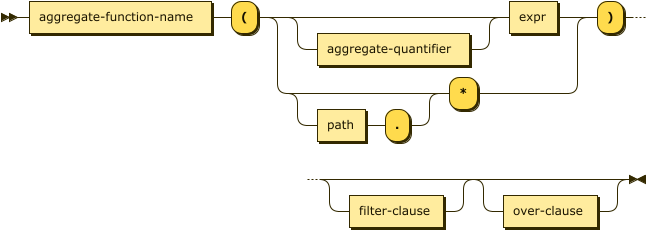
| aggregate-quantifier | |
| filter-clause | |
| over-clause |
Arguments
Aggregate functions take a single expression as an argument, which is used to compute the aggregate function.
The COUNT function can instead take a wildcard (*) or a path with a wildcard (path.*) as its argument.
Aggregate Quantifier
aggregate-quantifier ::= 'ALL' | 'DISTINCT'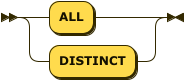
The aggregate quantifier determines whether the function aggregates all values in the group, or distinct values only.
ALL-
All objects are included in the computation.
DISTINCT-
Only distinct objects are included in the computation.
This quantifier can only be used with aggregate functions.
This quantifier is optional.
If omitted, the default value is ALL.
FILTER Clause
filter-clause ::= 'FILTER' '(' 'WHERE' cond ')'
The FILTER clause enables you to specify which values are included in the aggregate. This clause is available for aggregate functions, and aggregate functions used as window functions. (It is not permitted for dedicated window functions.)
The FILTER clause is useful when a query contains several aggregate functions, each of which requires a different condition.
- cond
-
[Required] Conditional expression. Values for which the condition resolves to TRUE are included in the aggregation.
The conditional expression is subject to the same rules as the conditional expression in the query WHERE clause, and the same rules as aggregation operands. It may not contain a subquery, a window function, or an outer reference.
| If the query block contains an aggregate function which uses the FILTER clause, the aggregation is not pushed down to the indexer. Refer to Grouping and Aggregate Pushdown for more details. |
OVER Clause
over-clause ::= 'OVER' ( '(' window-definition ')' | window-ref )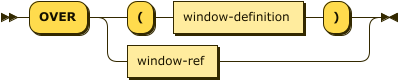
The OVER clause introduces the window specification for the function. There are two ways of specifying the window.
-
An inline window definition specifies the window directly within the function call. It is delimited by parentheses
()and has exactly the same syntax as the window definition in a WINDOW clause. For further details, refer to Window Definition. -
A window reference is an identifier which refers to a named window. The named window must be defined by a WINDOW clause in the same query block as the function call. For further details, refer to WINDOW Clause.
ARRAY_AGG( [ ALL | DISTINCT ] expression)
Return Value
With the ALL quantifier, or no quantifier, returns an array of the non-MISSING values in the group, including NULL values.
With the DISTINCT quantifier, returns an array of the distinct non-MISSING values in the group, including NULL values.
Examples
To try the examples in this section, set the query context to the inventory scope in the travel sample dataset.
For more information, see Query Context.
List all values of the Cleanliness reviews given:
SELECT ARRAY_AGG(reviews[0].ratings.Cleanliness) AS Reviews
FROM hotel;[
{
"Reviews": [
-1,
-1,
-1,
-1,
-1,
// ...
]
}
]List all unique values of the Cleanliness reviews given:
SELECT ARRAY_AGG(DISTINCT reviews[0].ratings.Cleanliness) AS Reviews
FROM hotel;[
{
"UniqueReviews": [
-1,
1,
2,
3,
4,
5
]
}
]AVG( [ ALL | DISTINCT ] expression)
This function has an alias MEAN().
Return Value
With the ALL quantifier, or no quantifier, returns the arithmetic mean (average) of all the number values in the group.
With the DISTINCT quantifier, returns the arithmetic mean (average) of all the distinct number values in the group.
Returns NULL if there are no number values in the group.
Examples
To try the examples in this section, set the query context to the inventory scope in the travel sample dataset.
For more information, see Query Context.
Find the average altitude of airports in the airport keyspace:
SELECT AVG(geo.alt) AS AverageAltitude FROM airport;[
{
"AverageAltitude": 870.1651422764228
}
]Find the average number of stops per route vs. the average of distinct numbers of stops:
SELECT AVG(ALL stops) AS AvgAllStops FROM route;Results in 0.0002 since nearly all routes have 0 stops.
SELECT AVG(DISTINCT stops) AS AvgDistinctStops FROM route;Results in 0.5 since all routes have only 1 or 0 stops.
COUNT(*)
Return Value
Returns count of all the input rows for the group, regardless of value. [1]
Example
To try the examples in this section, set the query context to the inventory scope in the travel sample dataset.
For more information, see Query Context.
Find the number of documents in the landmark keyspace:
SELECT COUNT(*) AS CountAll FROM landmark;[
{
"CountAll": 4495
}
]COUNT( [ ALL | DISTINCT ] expression)
Return Value
With the ALL quantifier, or no quantifier, returns count of all the non-NULL and non-MISSING values in the group. [1]
With the DISTINCT quantifier, returns count of all the distinct non-NULL and non-MISSING values in the group.
Examples
To try the examples in this section, set the query context to the inventory scope in the travel sample dataset.
For more information, see Query Context.
Find the number of documents with an airline route stop in the route keyspace regardless of its value:
SELECT COUNT(stops) AS CountOfStops FROM route;[
{
"CountOfStops": 24024
}
]Find the number of unique values of airline route stops in the route keyspace:
SELECT COUNT(DISTINCT stops) AS CountOfDistinctStops
FROM route;[
{
"CountOfSDistinctStops": 2 (1)
}
]| 1 | Results in 2 because there are only 0 or 1 stops. |
COUNTN( [ ALL | DISTINCT ] expression )
Return Value
With the ALL quantifier, or no quantifier, returns a count of all the numeric values in the group. [1]
With the DISTINCT quantifier, returns a count of all the distinct numeric values in the group.
Examples
The count of numeric values in a mixed group.
SELECT COUNTN(list.val) AS CountOfNumbers
FROM [
{"val":1},
{"val":1},
{"val":2},
{"val":"abc"}
] AS list;[
{
"CountOfNumbers": 3
}
]The count of unique numeric values in a mixed group.
SELECT COUNTN(DISTINCT list.val) AS CountOfNumbers
FROM [
{"val":1},
{"val":1},
{"val":2},
{"val":"abc"}
] AS list;[
{
"CountOfNumbers": 2
}
]MAX( [ ALL | DISTINCT ] expression)
Return Value
Returns the maximum non-NULL, non-MISSING value in the group in SQL++ collation order.
This function returns the same result with the ALL quantifier, the DISTINCT quantifier, or no quantifier.
Examples
To try the examples in this section, set the query context to the inventory scope in the travel sample dataset.
For more information, see Query Context.
Find the northernmost latitude of any hotel in the hotel keyspace:
SELECT MAX(geo.lat) AS MaxLatitude FROM hotel;[
{
"MaxLatitude": 60.15356
}
]Find the hotel whose name is last alphabetically in the hotel keyspace:
SELECT MAX(name) AS MaxName FROM hotel;[
{
"MaxName": "pentahotel Birmingham"
}
]That result might have been surprising since lowercase letters come after uppercase letters and are therefore "higher" than uppercase letters. To avoid this uppercase/lowercase confusion, you should first make all values uppercase or lowercase, as in the following example.
Find the hotel whose name is last alphabetically in the hotel keyspace:
SELECT MAX(UPPER(name)) AS MaxName FROM hotel;[
{
"MaxName": "YOSEMITE LODGE AT THE FALLS"
}
]MEAN( [ ALL | DISTINCT ] expression)
Alias for AVG().
MEDIAN( [ ALL | DISTINCT ] expression)
Return Value
With the ALL quantifier, or no quantifier, returns the median of all the number values in the group.
If there is an even number of number values, returns the mean of the median two values.
With the DISTINCT quantifier, returns the median of all the distinct number values in the group.
If there is an even number of distinct number values, returns the mean of the median two values.
Returns NULL if there are no number values in the group.
Examples
To try the examples in this section, set the query context to the inventory scope in the travel sample dataset.
For more information, see Query Context.
Find the median altitude of airports in the airport keyspace:
SELECT MEDIAN(geo.alt) AS MedianAltitude
FROM airport;[
{
"MedianAltitude": 361.5
}
]Find the median of distinct altitudes of airports in the airport keyspace:
SELECT MEDIAN(DISTINCT geo.alt) AS MedianAltitude FROM airport;[
{
"MedianDistinctAltitude": 758
}
]MIN( [ ALL | DISTINCT ] expression)
Return Value
Returns the minimum non-NULL, non-MISSING value in the group in SQL++ collation order.
This function returns the same result with the ALL quantifier, the DISTINCT quantifier, or no quantifier.
Examples
To try the examples in this section, set the query context to the inventory scope in the travel sample dataset.
For more information, see Query Context.
Find the southernmost latitude of any hotel in the hotel keyspace:
SELECT MIN(geo.lat) AS MinLatitude FROM hotel;[
{
"MinLatitude": 32.68092
}
]Find the hotel whose name is first alphabetically in the hotel keyspace:
SELECT MIN(name) AS MinName FROM hotel;[
{
"MinName": "'La Mirande Hotel"
}
]That result might have been surprising since some symbols come before letters and are therefore "lower" than letters. To avoid this symbol confusion, you can specify letters only, as in the following example.
Find the first hotel alphabetically in the hotel keyspace:
SELECT MIN(name) FILTER (WHERE SUBSTR(name,0)>="A") AS MinName
FROM hotel;[
{
"MinName": "AIRE NATURELLE LE GROZEAU Aire naturelle"
}
]STDDEV( [ ALL | DISTINCT ] expression)
Return Value
With the ALL quantifier, or no quantifier, returns the corrected sample standard deviation of all the number values in the group.
With the DISTINCT quantifier, returns the corrected sample standard deviation of all the distinct number values in the group.
Returns NULL if there are no number values in the group.
Examples
To try the examples in this section, set the query context to the inventory scope in the travel sample dataset.
For more information, see Query Context.
Find the sample standard deviation of all values:
SELECT STDDEV(reviews[0].ratings.Cleanliness) AS StdDev
FROM hotel
WHERE city="London";[
{
"StdDev": 2.0554275433769753
}
]Find the sample standard deviation of a single value:
SELECT STDDEV(reviews[0].ratings.Cleanliness) AS StdDevSingle
FROM hotel
WHERE name="Sachas Hotel";[
{
"StdDevSingle": 0 (1)
}
]| 1 | There is only one matching result in the input, so the function returns 0. |
Find the sample standard deviation of distinct values:
SELECT STDDEV(DISTINCT reviews[0].ratings.Cleanliness) AS StdDev
FROM hotel
WHERE city="London";[
{
"StdDevDistinct": 2.1602468994692865
}
]STDDEV_POP( [ ALL | DISTINCT ] expression)
Return Value
With the ALL quantifier, or no quantifier, returns the population standard deviation of all the number values in the group.
With the DISTINCT quantifier, returns the population standard deviation of all the distinct number values in the group.
Returns NULL if there are no number values in the group.
Examples
To try the examples in this section, set the query context to the inventory scope in the travel sample dataset.
For more information, see Query Context.
Find the population standard deviation of all values:
SELECT STDDEV_POP(reviews[0].ratings.Cleanliness) AS PopStdDev
FROM hotel
WHERE city="London";[
{
"PopStdDev": 2.0390493736539432
}
]Find the population standard deviation of distinct values:
SELECT STDDEV_POP(DISTINCT reviews[0].ratings.Cleanliness) AS PopStdDev
FROM hotel
WHERE city="London";[
{
"PopStdDevDistinct": 1.9720265943665387
}
]STDDEV_SAMP( [ ALL | DISTINCT ] expression)
A near-synonym for STDDEV().
The only difference is that STDDEV_SAMP() returns NULL if there is only one matching element.
Example
To try the examples in this section, set the query context to the inventory scope in the travel sample dataset.
For more information, see Query Context.
Find the sample standard deviation of a single value:
SELECT STDDEV_SAMP(reviews[0].ratings.Cleanliness) AS StdDevSingle
FROM hotel
WHERE name="Sachas Hotel";[
{
"StdDevSamp": null (1)
}
]| 1 | There is only one matching result in the input, so the function returns NULL. |
SUM( [ ALL | DISTINCT ] expression)
Return Value
With the ALL quantifier, or no quantifier, returns the sum of all the number values in the group.
With the DISTINCT quantifier, returns the arithmetic sum of all the distinct number values in the group.
Returns NULL if there are no number values in the group.
Examples
To try the examples in this section, set the query context to the inventory scope in the travel sample dataset.
For more information, see Query Context.
Find the sum total of all airline route stops in the route keyspace:
SELECT SUM(stops) AS SumOfStops FROM route;
In the route keyspace, nearly all flights are non-stop (0 stops) and only six flights have 1 stop, so we expect 6 flights of 1 stop each, a total of 6.
|
[
{
"SumOfStops": 6 (1)
}
]| 1 | There are 6 routes with 1 stop each. |
Find the sum total of all unique numbers of airline route stops in the route keyspace:
SELECT SUM(DISTINCT stops) AS SumOfStops FROM route;[
{
"SumOfDistinctStops": 1 (1)
}
]| 1 | There are only 0 and 1 stops per route; and 0 + 1 = 1. |
VARIANCE( [ ALL | DISTINCT ] expression)
Return Value
With the ALL quantifier, or no quantifier, returns the unbiased sample variance (the square of the corrected sample standard deviation) of all the number values in the group.
With the DISTINCT quantifier, returns the unbiased sample variance (the square of the corrected sample standard deviation) of all the distinct number values in the group.
Returns NULL if there are no number values in the group.
This function has a near-synonym VARIANCE_SAMP().
The only difference is that VARIANCE() returns NULL if there is only one matching element.
Examples
To try the examples in this section, set the query context to the inventory scope in the travel sample dataset.
For more information, see Query Context.
Find the sample variance of all values:
SELECT VARIANCE(reviews[0].ratings.Cleanliness) AS Variance
FROM hotel
WHERE city="London";[
{
"Variance": 4.224782386072708
}
]Find the sample variance of a single value:
SELECT VARIANCE(reviews[0].ratings.Cleanliness) AS VarianceSingle
FROM hotel
WHERE name="Sachas Hotel";[
{
"VarianceSingle": 0 (1)
}
]| 1 | There is only one matching result in the input, so the function returns 0. |
Find the sampling variance of distinct values:
SELECT VARIANCE(DISTINCT reviews[0].ratings.Cleanliness) AS Variance
FROM hotel
WHERE city="London";[
{
"VarianceDistinct": 4.666666666666667
}
]VARIANCE_POP( [ ALL | DISTINCT ] expression)
This function has an alias VAR_POP().
Return Value
With the ALL quantifier, or no quantifier, returns the population variance (the square of the population standard deviation) of all the number values in the group.
With the DISTINCT quantifier, returns the population variance (the square of the population standard deviation) of all the distinct number values in the group.
Returns NULL if there are no number values in the group.
Examples
To try the examples in this section, set the query context to the inventory scope in the travel sample dataset.
For more information, see Query Context.
Find the population variance of all values:
SELECT VARIANCE_POP(reviews[0].ratings.Cleanliness) AS PopVariance
FROM hotel
WHERE city="London";[
{
"PopVariance": 4.157722348198537
}
]Find the population variance of distinct values:
SELECT VARIANCE_POP(DISTINCT reviews[0].ratings.Cleanliness) AS PopVarianceDistinct
FROM hotel
WHERE city="London";[
{
"PopVarianceDistinct": 3.8888888888888893
}
]VARIANCE_SAMP( [ ALL | DISTINCT ] expression)
A near-synonym for VARIANCE().
The only difference is that VARIANCE_SAMP() returns NULL if there is only one matching element.
This function has an alias VAR_SAMP().
Example
To try the examples in this section, set the query context to the inventory scope in the travel sample dataset.
For more information, see Query Context.
Find the sample standard deviation of a single value:
SELECT VARIANCE_SAMP(reviews[0].ratings.Cleanliness) AS VarianceSamp
FROM hotel
WHERE name="Sachas Hotel";[
{
"VarianceSamp": null (1)
}
]| 1 | There is only one matching result in the input, so the function returns NULL. |
VAR_POP( [ ALL | DISTINCT ] expression)
Alias for VARIANCE_POP().
VAR_SAMP( [ ALL | DISTINCT ] expression)
Alias for VARIANCE_SAMP().
Formulas
The corrected sample standard deviation is calculated according to the following formula.
The population standard deviation is calculated according to the following formula.
Related Links
-
GROUP BY Clause for GROUP BY, LETTING, and HAVING clauses.
-
WINDOW Clause for WINDOW clauses.
-
Window Functions for window functions.