GROUP BY Clause
- Capella Operational
- reference
The GROUP BY clause arranges aggregate values into groups, based on one or more fields.
Purpose
Use the GROUP BY clause to arrange aggregate values into groups of one or more fields.
This GROUP BY clause follows the WHERE clause and can contain the optional GROUP AS, LETTING, and HAVING clauses.
Syntax
group-by-clause ::= 'GROUP' 'BY' group-term ( ',' group-term )*
group-as-clause? letting-clause? having-clause?
| letting-clause
| group-term | |
| group-as-clause | |
| letting-clause | |
| having-clause |
Group Term
group-term ::= expr ( ('AS')? alias )?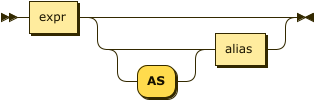
At least one group term is required.
- expr
-
String or expression representing an aggregate function or field to group together.
- alias
-
Assigns another name to the group term. For details, see AS Clause.
Assigning an alias to the group term is optional.
If you assign an alias, the AS keyword may be omitted.
GROUP AS Clause
group-as-clause ::= 'GROUP AS' alias
JSON is a hierarchical format, and a fully featured JSON query language needs to be able to produce hierarchies of its own, with computed data at every level of the hierarchy.
The key feature of SQL++ that makes this possible is the GROUP AS clause.
A query can include a GROUP AS clause only if it has a GROUP BY clause.
The effect of a GROUP BY clause is to hide the original objects in each group, exposing only the grouping expressions and special aggregation functions on the non-grouping fields.
The purpose of the GROUP AS clause is to make the original objects in the group visible to subsequent clauses.
As a result, the query can generate output data both for the group as a whole and for the individual objects inside the group.
For each group, GROUP AS preserves all of the objects in the group, as they were before grouping, in an array.
The name of the array is the alias in the GROUP AS clause.
You can then use the array name in the FROM clause of a subquery to process and return the individual objects in the group.
In the GROUP AS array, each object is wrapped in an outer object that gives it the name of the alias specified in the FROM clause, or its implicit alias if no alias was specified.
Identifying the objects with their aliases in this way helps avoid ambiguity.
For example, a query has a FROM clause of FROM airline as a, route as r, and a GROUP AS clause of GROUP AS g.
The result of the GROUP AS clause is an array of objects, each of which contains both an airline object and a route object.
These objects might contain field names that are the same, such as "id".
The resulting array g identifies each of the objects it contains separately with its alias, as follows:
[
{
"a": { an original airline object },
"r": { an original route object }
},
{
"a": { an original airline object },
"r": { an original route object }
},
...
]LETTING Clause
letting-clause ::= 'LETTING' alias '=' expr ( ',' alias '=' expr )*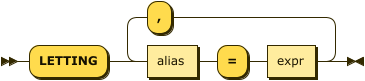
[Optional] Stores the result of a sub-expression in order to use it in subsequent clauses.
- alias
-
String or expression representing the name of the clause to be referred to.
- expr
-
String or expression representing the value of the
LETTINGaliasvariable.
HAVING Clause
having-clause ::= 'HAVING' cond
[Optional] To return items where aggregate values meet the specified conditions.
- cond
-
String or expression representing the clause of aggregate values.
Limitations
GROUP BY works only on a group key or aggregate function.
A query needs a predicate on a leading index key to ensure that the optimizer can select a secondary index for the query.
Without a matching predicate, the query will use the primary index.
The simplest predicate is WHERE leading-index-key IS NOT MISSING.
This is usually only necessary in queries which do not otherwise have a WHERE clause; for example, some GROUP BY and aggregate queries.
For more details, refer to Index Selection.
Examples
SELECT city City, COUNT(DISTINCT name) LandmarkCount
FROM landmark
GROUP BY city
ORDER BY LandmarkCount DESC
LIMIT 4;[
{
"City": "San Francisco",
"LandmarkCount": 797
},
{
"City": "London",
"LandmarkCount": 443
},
{
"City": "Los Angeles",
"LandmarkCount": 284
},
{
"City": "San Diego",
"LandmarkCount": 197
}
]SELECT country, COUNT(*) as count, g as group_docs
FROM airline a
GROUP BY country
GROUP AS g;[
{
"country": "United Kingdom",
"count": 39,
"group_docs": [
{
"a": {
"id": 10642,
"type": "airline",
"name": "Jc royal.britannica",
"iata": null,
"icao": "JRB",
"callsign": null,
"country": "United Kingdom"
}
},
{
"a": {
"id": 112,
"type": "airline",
"name": "Astraeus",
"iata": "5W",
"icao": "AEU",
"callsign": "FLYSTAR",
"country": "United Kingdom"
}
},
...
]
},
{
"country": "United States",
"count": 127,
"group_docs": [
{
"a": {
"id": 10,
"type": "airline",
"name": "40-Mile Air",
"iata": "Q5",
"icao": "MLA",
"callsign": "MILE-AIR",
"country": "United States"
}
},
{
"a": {
"id": 10123,
"type": "airline",
"name": "Texas Wings",
"iata": "TQ",
"icao": "TXW",
"callsign": "TXW",
"country": "United States"
}
},
...
]
},
{
"country": "France",
"count": 17,
"group_docs": [
{
"a": {
"id": 1191,
"type": "airline",
"name": "Air Austral",
"iata": "UU",
"icao": "REU",
"callsign": "REUNION",
"country": "France"
}
},
{
"a": {
"id": 1203,
"type": "airline",
"name": "Airlinair",
"iata": "A5",
"icao": "RLA",
"callsign": "AIRLINAIR",
"country": "France"
}
},
...
]
}
]SELECT country, COUNT(*) as count,
(SELECT g1.airline.name, g1.airline.id
FROM g g1
LIMIT 2)
AS airlines
FROM airline
GROUP BY country
GROUP AS g;[
{
"country": "United States",
"count": 127,
"airlines": [
{
"id": 10,
"name": "40-Mile Air"
},
{
"id": 10123,
"name": "Texas Wings"
}
]
},
{
"country": "France",
"count": 21,
"airlines": [
{
"id": 1191,
"name": "Air Austral"
},
{
"id": 1203,
"name": "Airlinair"
}
]
},
{
"country": "United Kingdom",
"count": 39,
"airlines": [
{
"id": 10642,
"name": "Jc royal.britannica"
},
{
"id": 112,
"name": "Astraeus"
}
]
}
] SELECT city City, COUNT(DISTINCT name) LandmarkCount
FROM landmark
GROUP BY city
LETTING MinimumThingsToSee = 400
HAVING COUNT(DISTINCT name) > MinimumThingsToSee;[
{
"City": "London",
"LandmarkCount": 443
},
{
"City": "San Francisco",
"LandmarkCount": 797
}
]SELECT city City, COUNT(DISTINCT name) LandmarkCount
FROM landmark
GROUP BY city
HAVING COUNT(DISTINCT name) > 180;[
{
"City": "London",
"LandmarkCount": 443
},
{
"City": "Los Angeles",
"LandmarkCount": 284
},
{
"City": "San Francisco",
"LandmarkCount": 797
},
{
"City": "San Diego",
"LandmarkCount": 197
}
]
The above HAVING clause must use the aggregate function COUNT instead of its alias LandmarkCount.
|
SELECT city City, COUNT(DISTINCT name) LandmarkCount
FROM landmark
GROUP BY city
HAVING city > "S"
ORDER BY city;[
{
"City": "Sacramento",
"LandmarkCount": 2
},
{
"City": "Saint Albans",
"LandmarkCount": 5
},
{
"City": "Saint Andrews",
"LandmarkCount": 13
},
{
"City": "Saint Annes Head",
"LandmarkCount": 1
},
// ...(execution: 1s docs: 138)
SELECT city City, COUNT(DISTINCT name) LandmarkCount
FROM landmark
WHERE city > "S"
GROUP BY city
ORDER BY city;[
{
"City": "Sacramento",
"LandmarkCount": 2
},
{
"City": "Saint Albans",
"LandmarkCount": 5
},
{
"City": "Saint Andrews",
"LandmarkCount": 13
},
{
"City": "Saint Annes Head",
"LandmarkCount": 1
},
// ...(execution: 480.2ms docs: 138)
The WHERE clause is faster because WHERE gets processed before any GROUP BY and doesn’t have access to aggregated values.
HAVING gets processed after GROUP BY and is used to constrain the resultset to only those with aggregated values.
|
SELECT Hemisphere, COUNT(DISTINCT name) AS LandmarkCount
FROM landmark AS l
GROUP BY CASE
WHEN l.geo.lon <0 THEN "West"
ELSE "East"
END AS Hemisphere;[
{
"Hemisphere": "East",
"LandmarkCount": 459
},
{
"Hemisphere": "West",
"LandmarkCount": 3885
}
]
The CASE expression categorizes each landmark into the Western hemisphere if its longitude is negative, or the Eastern hemisphere otherwise.
The alias in the GROUP BY clause enables you to refer to the CASE expression in the SELECT clause.
|
Related Links
-
For further examples, refer to Group By and Aggregate Performance.