Durability
Durability ensures the greatest likelihood of data-writes surviving unexpected anomalies, such as node-outages.
Understanding Durability
Writes to Couchbase-Server buckets can optionally be assigned durability requirements; which instruct Couchbase Server to update the specified document on multiple nodes in memory and/or disk locations across the cluster; before considering the write to be committed. The greater the number of memory and/or disk locations specified in the requirements, the greater the level of durability achieved.
Once the write has been committed as specified by the requirements, Couchbase Server notifies the client of success. If commitment was not possible, Couchbase Server notifies the client of failure; and the data retains its former value throughout the cluster.
This form of write is referred to as a durable or synchronous write.
Couchbase Server supports durability for up to two replicas: it does not support durability for three replicas.
Durability is used by Transactions, which support the atomicity of mutations across multiple documents.
Durability requirements can be specified by a client, assigned to a bucket, or both. Both Couchbase and Ephemeral buckets are supported: however, Ephemeral buckets only support durability requirements that do not involve persistence to disk.
Benefits and Costs
Durability allows developers to distinguish between regular and durable writes.
-
A regular write is asynchronous, and is not supported by durability. Such a write may be appropriate when writing data whose loss would produce only a minor inconvenience. For example, a single instance of sensor data, out of the tens of thousands of instances that are being continuously received.
-
A durable write is synchronous, and is supported by durability. Such a write may be appropriate when saving data whose loss could have a considerable, negative impact. For example, data corresponding to a financial transaction.
Note that in most cases, a durable write takes significantly longer than a regular write; due to the increased amount of either replication or persistence it demands from Couchbase Server, prior to completion. In considering whether to use durability, therefore, the application-designer must choose between the higher throughput (and lesser data-protection) provided by regular writes, and the greater data-protection (and lower throughput) provided by durable writes.
Majority
Durability requirements use the concept of majority, to indicate the number of configured Data Service nodes to which commitment is required, based on the number of replicas defined for the bucket. The correspondences are as follows:
| Number of Replicas | Number of Nodes Required for Majority |
|---|---|
0 |
1 |
1 |
2 |
2 |
2 |
3 |
Not supported |
|
In consequence of the correspondences listed above, if a bucket is configured with one replica, and a node fails, durable writes are immediately unavailable for any vBucket whose data resides on the failed node. |
Durability Requirements
Durability requirements that can be specified are:
-
Level. The level of durability required. The possible values are:
-
majority. The mutation must be replicated to (that is, held in the memory allocated to the bucket on) a majority of the Data Service nodes. Valid for both Couchbase and Ephemeral buckets.
-
majorityAndPersistActive. The mutation must be replicated to a majority of the Data Service nodes. Additionally, it must be persisted (that is, written and synchronised to disk) on the node hosting the active vBucket for the data. Valid for Couchbase buckets only.
-
persistToMajority. The mutation must be persisted to a majority of the Data Service nodes. Accordingly, it will be written to disk on those nodes. Valid for Couchbase buckets only.
-
-
Timeout. The number of milliseconds within which the durability requirements must be met. The SDK specifies a default of 2500.
Specifying Levels
Durability levels can be specified by a client, and can also be assigned to a bucket by an administrator. A level assigned to a bucket is subsequently enforced as the minimum level at which all writes to the bucket occur. Therefore:
-
If a level is specified by the client, and no level has been assigned to the bucket, the level specified by the client is enforced.
-
If no level is specified by the client (meaning that a non-durable write is being requested), but a level has been assigned to the bucket, the level assigned to the bucket is enforced.
-
If a level is specified by the client, and a level has also been assigned to the bucket, the higher level is enforced.
Process and Communication
A durable write is atomic. Client-reads of the value undergoing a durable write return the value that precedes the durable write. Clients that attempt to write to a key whose value is undergoing a durable write receive an error message from the active node, and may retry.
The lifecycle of a durable write is shown by the following, annotated diagram; which shows multiple clients' attempts to update and read a value, with the timeline moving from left to right.
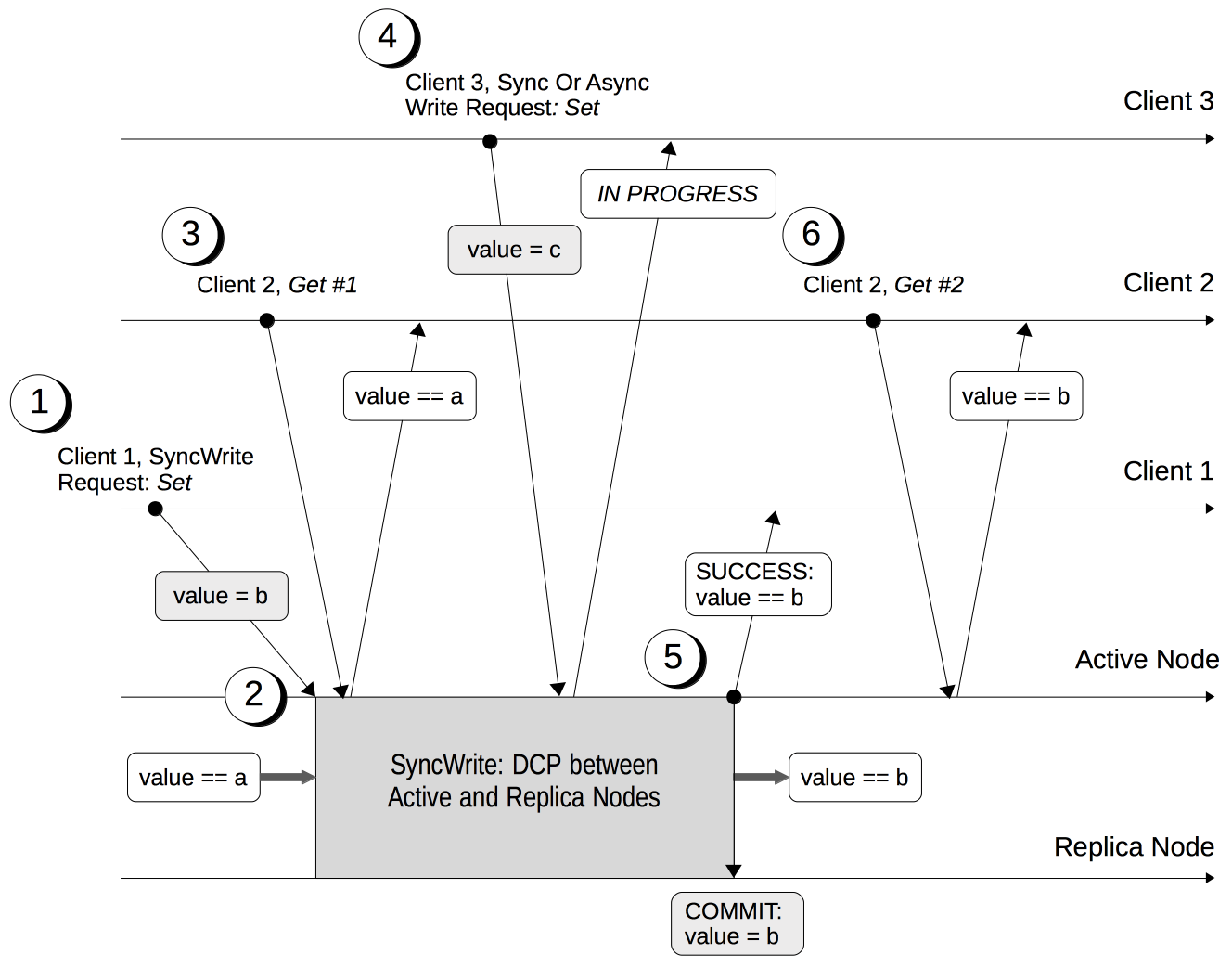
The annotations are as follows:
-
Client 1 specifies durability requirements for a durable write, to change a key’s existing value from a to b.
-
The Active Node receives the request, and the durable write process is initiated. Couchbase Server attempts to meet the client’s specified durability requirements.
-
During the durable write process, Client 2 performs a read on the value undergoing the durable write. Couchbase Server returns the value, a, that preceded the durable-write request.
-
During the durable-write process, Client 3 attempts either a durable write or a regular write on the value that is already undergoing a durable write. Couchbase Server returns a
SYNC_WRITE_IN_PROGRESSmessage, to indicate that the new write cannot occur. -
At the point the mutation has met the specified durability requirements, the Active Node commits the durable write, and sends a status response of
SUCCESSto Client 1. -
After the durable-write process, Client 2 performs a second read on the value. Couchbase Server returns the value, b, committed by the durable write. Indeed, from this point, all clients see the value b.
If Couchbase Server aborts a durable write, all mutations to active and replica vBuckets in memory and on disk are rolled back, and all copies of the data are reverted to their value from before the data-write. Couchbase Server duly informs the client. See Failure Scenarios, below.
In some circumstances, rather than acknowledging to a client that the durable write has succeeded, Couchbase Server acknowledges an ambiguous outcome: for example, due to the client-specified timeout having elapsed. See Handling Ambiguous Results, below.
Subsequent to a durable write’s commitment and due acknowledgement, Couchbase Server continues the process of replication and persistence, until all active and replica vBuckets, both in memory and on disk, have been appropriately updated across all nodes.
Regular Writes
A write that occurs without durability is considered a regular (that is asynchronous) write. No durability requirement is imposed. Couchbase Server acknowledges success to the client as soon as the data is in the memory of the node hosting the active vBucket: Couchbase Server does not confirm that the write has been propagated to any replica. A regular write therefore provides no guarantee of durability.
Failure Scenarios
A durable write fails in the following situations:
-
Server timeout exceeded. The active node aborts the durable write, instructs all replica nodes also to abort the pending write, and informs the client that the durable write has had an ambiguous result. See Handling Ambiguous Results, below.
-
Replica node fails while SyncWrite is pending (that is, before the active node can identify whether the node hosted a replica). If enough alternative replica nodes can be identified, the durable write can proceed. Otherwise, the active node waits until a server-side timeout has expired; then aborts the durable write, and duly informs the client that the durable write has had an ambiguous result.
-
Active node fails while SyncWrite is pending. This disconnects the client, which must assume that the result of the durable write has proved ambiguous. If the active node is failed over, a replica is promoted from a replica node: depending on how advanced the durable write was at the time of active-node failure, the durable write may proceed.
-
Write while SyncWrite is pending. A client that attempts a durable or an asynchronous write on a key whose value is currently undergoing a durable write receives a
SYNC_WRITE_IN_PROGRESSmessage, to indicate that the new write cannot currently proceed. The client may retry.
Handling Ambiguous Results
Couchbase Server informs the client of an ambiguous result whenever Couchbase Server cannot confirm that an intended commit was successful. This situation may be caused by node-failure, network-failure, or timeout.
If a client receives notification of an ambiguous result, and the attempted durable write is idempotent, the durable write can be re-attempted. If the attempted durable write is not idempotent, the options are:
-
Verify the current state of the saved data; and re-attempt the durable write if appropriate.
-
Return an error to the user.
Rebalance
The rebalance process moves active and replica vBuckets across nodes, to ensure optimal availability. During the process, clients’ access to data is uninterrupted. The durable-write process is likewise uninterrupted by rebalance, and continues throughout the rebalance process.
Performance
The performance of durable writes may be optimized by the appropriate allocation of writer threads. See Threading for conceptual information, and Data Settings for practical steps.
Protection Guarantees: Overview
When the durable-write process is complete, the application is notified that commitment has occurred. During the time-period that starts at the point of commitment, and lasts until the point at which the new data has been fully propagated throughout the cluster (this being potentially but not necessarily later than the point of commitment), if an outage occurs, the new data is guaranteed to be protected from loss — within certain constraints. The constraints are related to the level of durability specified, the nature of the outage, and the number of replicas. The guarantees and associated constraints are stated on this page, below.
Replica-Count Restriction
Couchbase-Server durability supports buckets with up to two replicas.
It does not support buckets with three replicas.
If a durable write is attempted on a bucket that has been configured with three replicas, the write fails with an EDurabilityImpossible message.
Protection Guarantees and Automatic Failover
Automatic Failover removes a non-responsive node from the cluster automatically, following an administrator-configured timeout. Active vBuckets thereby lost are replaced by the promotion of replica vBuckets, on the surviving nodes. A maximum of three sequential automatic failovers can be configured to occur.
In cases where commitment based on persistToMajority has occurred, but no further propagation of the new data across the cluster has yet occurred, automatic failover of the nodes containing the new data results in the data’s loss — since no updated replica vBucket yet exists elsewhere on the cluster.
For example, if a bucket has two replicas, the total number of nodes on which the data resides is three; and the majority of nodes, on which persistence must occur prior to commitment, is two. After commitment, if those two nodes become unresponsive, automatic failover, if configured to occur up to a maximum of two times, allows those two nodes to be failed over before the durable write has been made persistent on the third node. In such a case, the durable write is lost, and the success message already delivered to the application rendered false.
To prevent this, and thereby maintain guaranteed protection, at least one of the unresponsive nodes containing the new data should not be failed over. Therefore, auto-failover should be configured to occur sequentially only up to the number of times that supports this requirement.
Protection Guarantees: One Replica
When one replica has been defined, from the point of commitment until the new data has been fully propagated across the cluster, protection guarantees are as follows:
Level |
Failure(s) |
Description |
majority |
The active node fails, and is automatically failed over. |
The new data is lost from the memory of the active node; but exists in the memory of the replica node. The replica vBucket is promoted to active status on the replica node, and the new data is thus preserved. |
majorityAndPersistActive |
The active node fails, and is automatically failed over. |
The new data is lost from the memory and disk of the active node; but exists in the memory of the replica node. The replica vBucket is promoted to active status on the replica node, and the new data is thus preserved. |
The active node fails, but restarts before auto-failover occurs. |
The new data is lost from the memory of the active node; but exists on the disk of the active node, and is thereby recovered when the active node has restarted. |
persistToMajority |
The active node fails, and is automatically failed over. |
The new data is lost from the memory and disk of the active node; but exists in the memory and disk of the replica node. The replica vBucket is promoted to active status on the replica node, and the new data is thus preserved. |
The active node fails, but restarts before auto-failover occurs. |
The new data is lost from the memory of the active node; but exists on the disk of the active node, and is thereby recovered when the active node has restarted. |
|
The active node fails, and is automatically failed over. Then, the promoted replica node itself fails, and then restarts. |
The new data is lost from the memory and disk of the active node, but exists in the memory and on the disk of the replica node; and is promoted there to active status. Then, the promoted replica node itself fails, and the new data is temporarily unavailable. However, when the promoted replica node has restarted, the new data again becomes available on disk. To ensure auto-failover does not conflict with guaranteed protection, when two replicas have been configured, establish |
Protection Guarantees: Two Replicas
The durability protection guarantees for two replicas are identical to those described above, for One Replica.
This is because majority is 2 for both cases: see the table in Majority, above.
Commitment therefore occurs without the second replica being guaranteed an update.
To ensure auto-failover does not conflict with guaranteed protection, when two replicas have been configured, establish 1 as the maximum number of sequential automatic failovers that can take place without administrator intervention.