Configure Queries
You can configure the Query service using cluster-level query settings, node-level query settings, and request-level query parameters.
Overview
There are three ways of configuring the Query service:
-
Specify cluster-level settings for all nodes running the Query service in the cluster.
-
Specify node-level settings for a single node running the Query service.
-
Specify parameters for individual requests.
You must set and use cluster-level query settings, node-level query settings, and request-level parameters in different ways.
| Set Per | Set By | Set On | Set Via | |
|---|---|---|---|---|
Cluster-level query settings [note] |
Cluster |
System administrator |
Server side |
The CLI, cURL statements, or the UI |
Node-level query settings [note] |
Service Node |
System administrator |
Server side |
cURL statements |
Request-level parameters |
Request (statement) |
Each user |
Client side |
|
| Cluster-level settings and node-level settings are collectively referred to as service-level settings. |
How Setting Levels Interact
Some query settings are cluster-level, node-level, or request-level only. Other query settings apply to more than one level with slightly different names.
How Cluster-Level Settings Affect Node-Level Settings
If a cluster-level setting has an equivalent node-level setting, then changing the cluster-level setting overwrites the node-level setting for all Query nodes in the cluster.
You can change a node-level setting for a single node to be different to the equivalent cluster-level setting. Changing the node-level setting does not affect the equivalent cluster-level setting. However, you should note that the node-level setting may be overwritten by subsequent changes at the cluster-level. In particular, specifying query settings via the CLI or the UI makes changes at the cluster-level.
How Node-Level Settings Affect Request-Level Parameters
If a request-level parameter has an equivalent node-level setting, the node-level setting usually acts as the default for the request-level parameter, as described in the tables below. Setting a request-level parameter overrides the equivalent node-level setting.
Furthermore, for numeric values, if a request-level parameter has an equivalent node-level setting, the node-level setting dictates the upper-bound value of the request-level parameter.
For example, if the node-level timeout is set to 500, then the request-level parameter cannot be set to 501 or any value higher.
All Query Settings
| Cluster-Level Only Settings | Node-Level Only Settings | Request-Level Only Parameters |
|---|---|---|
args |
| Cluster-Level Name | Node-Level Name | Request-Level Name |
|---|---|---|
N/A |
| Cluster-Level Name | Node-Level Name | Request-Level Name |
|---|---|---|
N/A |
| Cluster-Level Name | Node-Level Name | Request-Level Name |
|---|---|---|
Cluster-Level Query Settings
To set a cluster-level query setting, do one of the following:
-
Use the Advanced Query Settings in the Couchbase Web Console.
-
Use the setting-query command at the command line.
-
Make a REST API call to the Query Settings REST API (
/settings/querySettingsendpoint).
-
Web Console
-
Command Line
-
REST API
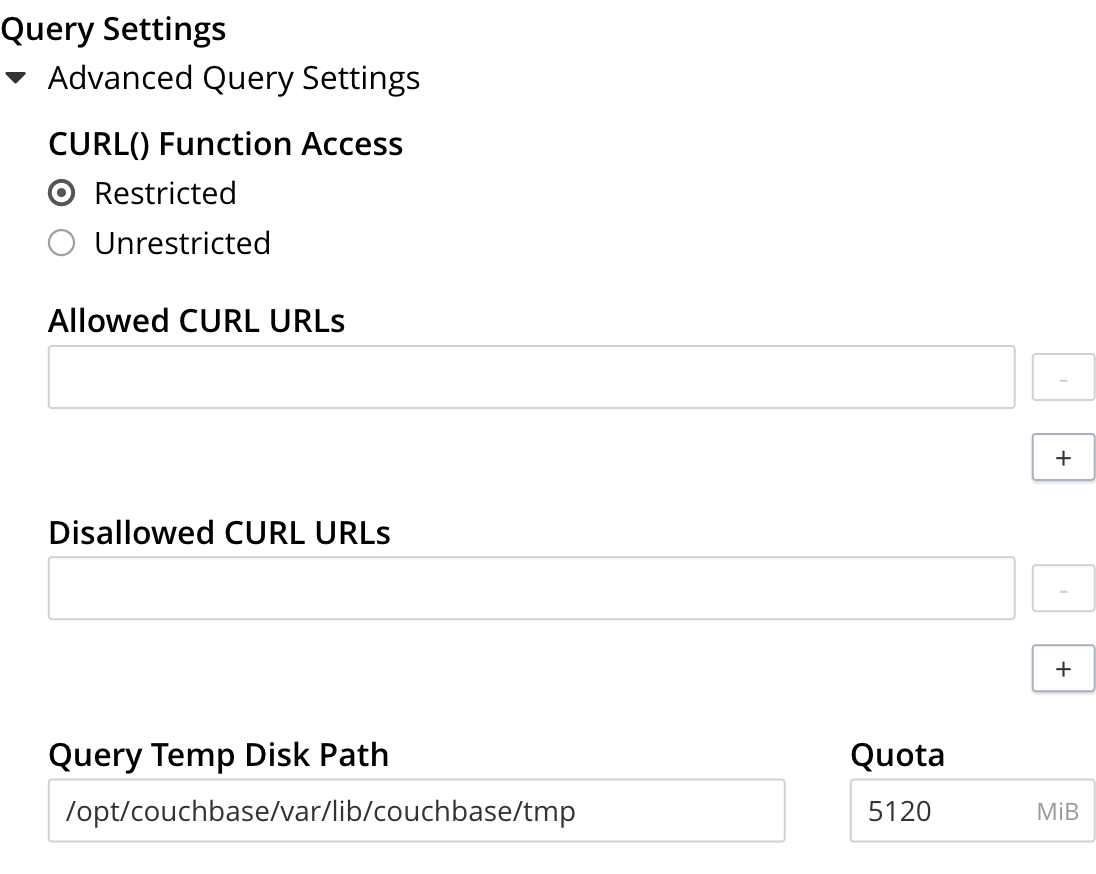
To set cluster-level settings in the Web Console:
-
Go to and click Advanced Query Settings to display the settings.
-
Specify the settings and click Save.
To set cluster-level settings at the command line, use the couchbase-cli setting-query command.
The following example retrieves the current cluster-level settings:
couchbase-cli setting-query -c http://localhost:8091 -u Administrator \
-p password --getThe following example sets the cluster-level maximum parallelism and log level settings:
couchbase-cli setting-query -c http://localhost:8091 -u Administrator \
-p password --set --log-level debug --max-parallelism 4To set cluster-level settings with the REST API, specify the parameters in the request body.
The following example retrieves the current cluster-level settings:
curl -v -u Administrator:password \
http://localhost:8091/settings/querySettingsThe following example sets the cluster-level maximum parallelism and log level settings:
curl -v -X POST -u Administrator:password \
http://localhost:8091/settings/querySettings \
-d 'queryLogLevel=debug' \
-d 'queryMaxParallelism=4'The table below contains details of all cluster-level query settings.
| Property | Schema | |
|---|---|---|
queryCleanupClientAttempts |
When enabled, the Query service preferentially aims to clean up just transactions that it has created, leaving transactions for the distributed cleanup process only when it is forced to. The node-level Default: |
Boolean |
queryCleanupLostAttempts |
When enabled, the Query service takes part in the distributed cleanup process, and cleans up expired transactions created by any client. The node-level Default: |
Boolean |
queryCleanupWindow |
Specifies how frequently the Query service checks its subset of active transaction records for cleanup. Decreasing this setting causes expiration transactions to be found more swiftly, with the tradeoff of increasing the number of reads per second used for the scanning process. The value for this setting is a string.
Its format includes an amount and a mandatory unit, e.g.
The node-level Default: |
String (duration) |
queryCompletedLimit |
Sets the number of requests to be logged in the completed requests catalog. As new completed requests are added, old ones are removed. Increase this when the completed request keyspace is not big enough to track the slow requests, such as when you want a larger sample of slow requests. Refer to Configure the Completed Requests for more information and examples. The node-level Default: |
Integer (int32) |
queryCompletedMaxPlanSize |
A plan size in bytes. Limits the size of query execution plans that can be logged in the completed requests catalog. Values larger than the maximum limit are silently treated as the maximum limit. Queries with plans larger than this are not logged. You must obtain execution plans for such queries via profiling or using the EXPLAIN statement. Refer to Configure the Completed Requests for more information. The node-level Default: |
Integer (int32) |
queryCompletedThreshold |
A duration in milliseconds. All completed queries lasting longer than this threshold are logged in the completed requests catalog. Specify Refer to Configure the Completed Requests for more information and examples. The node-level Default: |
Integer (int32) |
queryLogLevel |
Log level used in the logger. All values, in descending order of data:
The node-level Values: |
String |
queryMaxParallelism |
Specifies the maximum parallelism for queries on all Query nodes in the cluster. If the value is zero or negative, the maximum parallelism is restricted to the number of allowed cores. Similarly, if the value is greater than the number of allowed cores, the maximum parallelism is restricted to the number of allowed cores. (The number of allowed cores is the same as the number of logical CPUs. In Community Edition, the number of allowed cores cannot be greater than 4. In Enterprise Edition, there is no limit to the number of allowed cores.) The node-level In addition, there is a request-level NOTE: To enable queries to run in parallel, you must specify the cluster-level Refer to Max Parallelism for more information. Default: |
Integer (int32) |
queryMemoryQuota |
Specifies the maximum amount of memory a request may use on any Query node in the cluster, in MB. This parameter enforces a ceiling on the memory used for the tracked documents required for processing a request. It does not take into account any other memory that might be used to process a request, such as the stack, the operators, or some intermediate values. Within a transaction, this setting enforces the memory quota for the transaction by tracking the delta table and the transaction log (approximately). The node-level In addition, there is a request-level Default: |
Integer (int32) |
queryN1qlFeatCtrl |
SQL++ feature control. This setting is provided for technical support only. The node-level |
Integer (int32) |
queryNodeQuota |
Sets the soft memory limit for every Query node in the cluster, in MB. The garbage collector tries to keep below this target. It is not a hard, absolute limit, and memory usage may exceed this value. When set to The node-level Default: |
Integer (int32) |
queryNodeQuotaValPercent |
The percentage of the The node-level Default: |
Integer (int32) |
queryNumAtrs |
Specifies the total number of active transaction records for all Query nodes in the cluster. The node-level In addition, there is a request-level Default: |
Integer (int32) |
queryNumCpus |
The number of CPUs the Query service can use on any Query node in the cluster. Note that this setting requires a restart of the Query service to take effect. When set to The number of CPUs can never be greater than the number of logical CPUs. In Community Edition, the number of allowed CPUs cannot be greater than 4. In Enterprise Edition, there is no limit to the number of allowed CPUs. The node-level Default: |
Integer (int32) |
queryPipelineBatch |
Controls the number of items execution operators can batch for Fetch from the KV. The node-level In addition, the request-level Default: |
Integer (int32) |
queryPipelineCap |
Maximum number of items each execution operator can buffer between various operators. The node-level In addition, the request-level Default: |
Integer (int32) |
queryPreparedLimit |
Maximum number of prepared statements in the cache. When this cache reaches the limit, the least recently used prepared statements will be discarded as new prepared statements are created. The node-level Default: |
Integer (int32) |
queryScanCap |
Maximum buffered channel size between the indexer client and the query service for index scans. This parameter controls when to use scan backfill. Use The node-level In addition, the request-level Default: |
Integer (int32) |
queryTimeout |
Maximum time to spend on the request before timing out (ns). The value for this setting is an integer, representing a duration in nanoseconds. It must not be delimited by quotes, and must not include a unit. Specify The node-level In addition, the request-level Default: |
Long (int64) |
queryTxTimeout |
Maximum time to spend on a transaction before timing out.
This setting only applies to requests containing the The value for this setting is a string.
Its format includes an amount and a mandatory unit, e.g.
Specify The node-level In addition, there is a request-level Default: |
String (duration) |
queryTmpSpaceDir |
The path to which the indexer writes temporary backfill files, to store any transient data during query processing. The specified path must already exist. Only absolute paths are allowed. The default path is Example: |
String |
queryTmpSpaceSize |
The maximum size of temporary backfill files (MB). Setting the size to The maximum size is limited only by the available disk space. Default: |
Integer (int32) |
queryUseCBO |
Specifies whether the cost-based optimizer is enabled. The node-level In addition, the request-level Default: |
Boolean |
queryUseReplica |
Specifies whether a query can fetch data from a replica vBucket if active vBuckets are inaccessible. The possible values are:
The node-level In addition, the request-level Do not enable read from replica when you require consistent results. Only SELECT queries that are not within a transaction can read from replica. Reading from replica is only possible if the cluster uses Couchbase Server 7.6.0 or later. Note that KV range scans cannot currently be started on a replica vBucket. If a query uses sequential scan and a data node becomes unavailable, the query might return an error, even if read from replica is enabled for the request. Values: |
String |
queryCurlWhitelist |
An object which determines which URLs may be accessed by the |
Access
| Property | Schema | |
|---|---|---|
all_access |
Defines whether the user has access to all URLs, or only URLs specified by the access list. This field set must be set to Setting this field to |
Boolean |
allowed_urls |
An array of strings, each of which is a URL to which you wish to grant access. Each URL is a prefix match. The CURL() function will allow any URL that starts with this value. For example, if you wish to allow access to all Google APIs, add the URL Note that each URL must include the port, protocol, and all other components of the URL. |
String array |
disallowed_urls |
An array of strings, each of which is a URL that will be restricted for all roles. Each URL is a prefix match. The CURL() function will disallow any URL that starts with this value. If both Note that each URL must include the port, protocol, and all other components of the URL. |
String array |
Node-Level Query Settings
To set a node-level query setting:
-
Make a REST API call to the Admin REST API (
/admin/settingsendpoint).
You cannot set a query setting for an individual node using the Couchbase Web Console or the command line.
-
REST API
To set node-level settings with the REST API, specify the parameters in the request body.
The following example retrieves the current node-level settings:
curl $BASE_URL/admin/settings -u $USER:$PASSWORDThe following example sets the node-level profile parameter:
curl $BASE_URL/admin/settings -u $USER:$PASSWORD \
-H 'Content-Type: application/json' \
-d '{"profile": "phases"}'For more examples, see Manage and Monitor Queries.
The table below contains details of all node-level query settings.
| Property | Schema | |
|---|---|---|
atrcollection |
Specifies the collection where active transaction records are stored. The collection must be present. If not specified, the active transaction record is stored in the default collection in the default scope in the bucket containing the first mutated document within the transaction. The value must be a string in the form The request-level Default: |
String |
auto-prepare |
Specifies whether the query engine should create a prepared statement every time a SQL++ request is submitted, whether the PREPARE statement is included or not. Refer to Auto-Prepare for more information. Default: |
Boolean |
cleanupclientattempts |
When enabled, the Query service preferentially aims to clean up just transactions that it has created, leaving transactions for the distributed cleanup process only when it is forced to. The cluster-level Default: |
Boolean |
cleanuplostattempts |
When enabled, the Query service takes part in the distributed cleanup process, and cleans up expired transactions created by any client. The cluster-level Default: |
Boolean |
cleanupwindow |
Specifies how frequently the Query service checks its subset of active transaction records for cleanup. Decreasing this setting causes expiration transactions to be found more swiftly, with the tradeoff of increasing the number of reads per second used for the scanning process. The value for this setting is a string.
Its format includes an amount and a mandatory unit, e.g.
The cluster-level Default: |
String (duration) |
completed |
A nested object that sets the parameters for the completed requests catalog. All completed requests that match these parameters are tracked in the completed requests catalog. Refer to Configure Completed Requests for more information and examples. |
|
completed-limit |
Sets the number of requests to be logged in the completed requests catalog. As new completed requests are added, old ones are removed. Increase this when the completed request keyspace is not big enough to track the slow requests, such as when you want a larger sample of slow requests. Refer to Configure Completed Requests for more information and examples. The cluster-level Default: |
Integer (int32) |
completed-max-plan-size |
A plan size in bytes. Limits the size of query execution plans that can be logged in the completed requests catalog. Values larger than the maximum limit are silently treated as the maximum limit. Queries with plans larger than this are not logged. You must obtain execution plans for such queries via profiling or using the EXPLAIN statement. Refer to Configure Completed Requests for more information. The cluster-level Default: |
Integer (int32) |
completed-stream-size |
Couchbase Server 7.6.4 A file size in MiB.
When specified, completed requests are saved to the Couchbase Server Specify Completed request streaming is available in Couchbase Server 7.6.4 and later. Refer to Stream Completed Requests for more information and examples. |
Integer (int32) |
completed-threshold |
A duration in milliseconds. All completed queries lasting longer than this threshold are logged in the completed requests catalog. Specify Refer to Configure Completed Requests for more information and examples. The cluster-level Default: |
Integer (int32) |
controls |
Specifies if there should be a controls section returned with the request results. When set to NOTE: If the request qualifies for caching, these values will also be cached in the The request-level Default: |
Boolean |
cpuprofile |
The absolute path and filename to write the CPU profile to a local file. The output file includes a controls section and performance measurements, such as memory allocation and garbage collection, to pinpoint bottlenecks and ways to improve your code execution. NOTE: If To stop Default: |
String |
debug |
Use debug mode. When set to Default: |
Boolean |
distribute |
This field is only available with the POST method. When specified alongside other settings, this field instructs the node that is processing the request to cascade those settings to all other query nodes. The actual value of this field is ignored. Example: |
Boolean |
functions-limit |
Maximum number of user-defined functions. Default: |
Integer (int32) |
keep-alive-length |
Maximum size of buffered result. Default: |
Integer (int32) |
loglevel |
Log level used in the logger. All values, in descending order of data:
The cluster-level Values: |
String |
max-index-api |
Max index API. This setting is provided for technical support only. |
Integer (int32) |
max-parallelism |
Specifies the maximum parallelism for queries on this node. If the value is zero or negative, the maximum parallelism is restricted to the number of allowed cores. Similarly, if the value is greater than the number of allowed cores, the maximum parallelism is restricted to the number of allowed cores. (The number of allowed cores is the same as the number of logical CPUs. In Community Edition, the number of allowed cores cannot be greater than 4. In Enterprise Edition, there is no limit to the number of allowed cores.) The cluster-level In addition, there is a request-level NOTE: To enable queries to run in parallel, you must specify the cluster-level Refer to Max Parallelism for more information. Default: |
Integer (int32) |
memory-quota |
Specifies the maximum amount of memory a request may use on this node, in MB.
Note that the overall node memory quota is this setting multiplied by the node-level Specify This parameter enforces a ceiling on the memory used for the tracked documents required for processing a request. It does not take into account any other memory that might be used to process a request, such as the stack, the operators, or some intermediate values. Within a transaction, this setting enforces the memory quota for the transaction by tracking the delta table and the transaction log (approximately). The cluster-level In addition, the request-level Default: |
Integer (int32) |
memprofile |
Filename to write the diagnostic memory usage log. NOTE: If To stop Default: |
String |
mutexprofile |
Mutex profile. This setting is provided for technical support only. Default: |
Boolean |
n1ql-feat-ctrl |
SQL++ feature control. This setting is provided for technical support only. The value may be an integer, or a string representing a hexadecimal number. The cluster-level Default: |
Integer (int32) |
node-quota |
Sets the soft memory limit for this node, in MB. The garbage collector tries to keep below this target. It is not a hard, absolute limit, and memory usage may exceed this value. When set to The cluster-level Default: |
Integer (int32) |
node-quota-val-percent |
The percentage of the The cluster-level Default: |
Integer (int32) |
num-cpus |
The number of CPUs the Query service can use on this node. Note that this setting requires a restart of the Query service to take effect. When set to The number of CPUs can never be greater than the number of logical CPUs. In Community Edition, the number of allowed CPUs cannot be greater than 4. In Enterprise Edition, there is no limit to the number of allowed CPUs. The cluster-level Default: |
Integer (int32) |
numatrs |
Specifies the total number of active transaction records. The cluster-level In addition, the request-level |
String |
pipeline-batch |
Controls the number of items execution operators can batch for Fetch from the KV. The cluster-level In addition, the request-level Default: |
Integer (int32) |
pipeline-cap |
Maximum number of items each execution operator can buffer between various operators. The cluster-level In addition, the request-level Default: |
Integer (int32) |
plus-servicers |
The number of service threads for transactions where the scan consistency is Example: |
Integer (int32) |
prepared-limit |
Maximum number of prepared statements in the cache. When this cache reaches the limit, the least recently used prepared statements will be discarded as new prepared statements are created. The cluster-level Default: |
Integer (int32) |
pretty |
Specifies whether query results are returned in pretty format. The request-level Default: |
Boolean |
profile |
Specifies if there should be a profile section returned with the request results. The valid values are:
NOTE: If Refer to Monitoring and Profiling Details for more information and examples. The request-level Values: |
String |
request-size-cap |
Maximum size of a request. Default: |
Integer (int32) |
scan-cap |
Maximum buffered channel size between the indexer client and the query service for index scans. This parameter controls when to use scan backfill. Use The cluster-level In addition, the request-level Default: |
Integer (int32) |
servicers |
The number of service threads for the query. The default is 4 times the number of cores on the query node. Note that the overall node memory quota is this setting multiplied by the node-level Default: |
Integer (int32) |
timeout |
Maximum time to spend on the request before timing out (ns). The value for this setting is an integer, representing a duration in nanoseconds. It must not be delimited by quotes, and must not include a unit. Specify The cluster-level In addition, the request-level Default: |
Long (int64) |
txtimeout |
Maximum time to spend on a transaction before timing out (ns).
This setting only applies to requests containing the The value for this setting is an integer, representing a duration in nanoseconds. It must not be delimited by quotes, and must not include a unit. Specify The cluster-level In addition, the request-level Default: |
Long (int64) |
use-cbo |
Specifies whether the cost-based optimizer is enabled. The cluster-level In addition, the request-level Default: |
Boolean |
use-replica |
Specifies whether a query can fetch data from a replica vBucket if active vBuckets are inaccessible. The possible values are:
The cluster-level In addition, the request-level Do not enable read from replica when you require consistent results. Only SELECT queries that are not within a transaction can read from replica. Reading from replica is only possible if the cluster uses Couchbase Server 7.6.0 or later. Note that KV range scans cannot currently be started on a replica vBucket. If a query uses sequential scan and a data node becomes unavailable, the query might return an error, even if read from replica is enabled for the request. Values: |
String |
Logging Parameters
| Property | Schema | |
|---|---|---|
aborted |
If true, all requests that generate a panic are logged. Default: |
Boolean |
client |
The IP address of the client. If specified, all completed requests from this IP address are logged. Default: |
String |
context |
The opaque ID or context provided by the client. If specified, all completed requests with this client context ID are logged. Refer to the request-level |
String |
error |
An error number. If specified, all completed queries returning this error number are logged. Default: |
Integer (int32) |
tag |
A unique string which tags a set of qualifiers. Refer to Configure Completed Requests for more information. Default: |
String |
threshold |
A duration in milliseconds. If specified, all completed queries lasting longer than this threshold are logged. This is another way of specifying the node-level Default: |
Integer (int32) |
user |
A user name, as given in the request credentials. If specified, all completed queries with this user name are logged. Default: |
String |
Request-Level Parameters
To set a request-level parameter, do one of the following:
-
Use the Run-Time Preferences window in the Query Workbench.
-
Use the cbq shell at the command line.
-
Make a REST API call to the Query Service REST API (
/query/serviceendpoint). -
Use an SDK client program.
Generally, use the cbq shell or the Query Workbench as a sandbox to test queries on your local machine.
Use a REST API call or an SDK client program for your production queries.
-
Web Console
-
Command Line
-
REST API
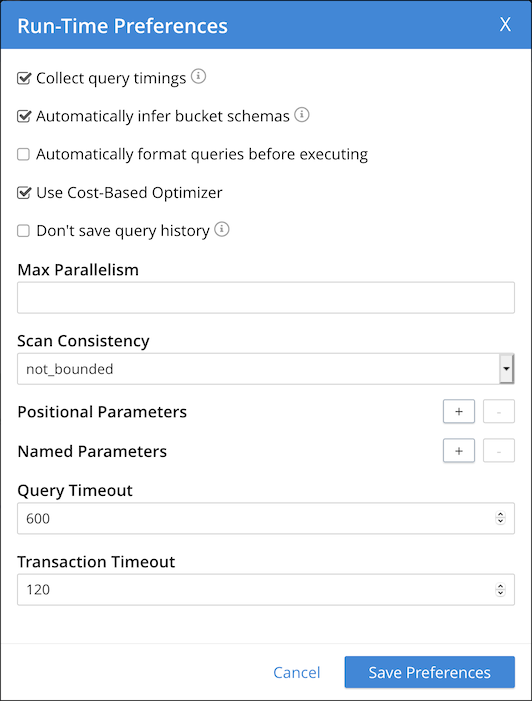
To set request-level preferences in the Query Workbench:
-
Go to and click the cog icon to display the Run-Time Preferences window.
-
Specify the preferences — if a preference is not explicitly listed, click + next to Named Parameters and add its name and value.
-
Click Save Preferences.
For more examples, see the Couchbase Transactions guide.
To set request-level parameters in cbq, use the \SET command.
The parameter name must be prefixed by a hyphen.
The following example sets the request-level timeout, pretty-print, and max parallelism parameters, and runs a query:
\SET -timeout "30m";
\SET -pretty true;
\SET -max_parallelism 3;
SELECT * FROM "world" AS hello;For more examples, see Parameter Manipulation in the cbq documentation.
To set request-level parameters with the REST API, specify the parameters in the request body or the query URI.
The following example sets the request-level timeout, pretty-print, and max parallelism parameters, and runs a query:
curl http://localhost:8093/query/service -u Administrator:password \
-d 'statement=SELECT * FROM "world" AS hello;
& timeout=30m
& pretty=true
& max_parallelism=3'For more examples, see the Query Service REST API examples.
The table below contains details of all request-level parameters, along with examples.
| Property | Schema | |
|---|---|---|
args |
Supplies the values for positional parameters in the statement. Applicable if the statement or prepared statement contains 1 or more positional parameters. The value is an array of JSON values, one for each positional parameter in the statement. Refer to Named Parameters and Positional Parameters for details. Example: |
Any Type array |
atrcollection |
Specifies the collection where the active transaction record (ATR) is stored. The collection must be present. If not specified, the ATR is stored in the default collection in the default scope in the bucket containing the first mutated document within the transaction. The value must be a string in the form The node-level Example: |
String |
auto_execute |
Specifies that prepared statements should be executed automatically as soon as they are created. This saves you from having to make two separate requests in cases where you want to prepare a statement and execute it immediately. Refer to Auto-Execute for more information. Default: |
Boolean |
client_context_id |
A piece of data supplied by the client that is echoed in the response, if present. SQL++ is agnostic about the content of this parameter; it is just echoed in the response.
|
String |
compression |
Compression format to use for response data on the wire. Values are case-insensitive. Values: |
String |
controls |
Specifies if there should be a controls section returned with the request results. When set to If the request qualifies for caching, these values will also be cached in the The node-level Example: |
Boolean |
creds |
Specifies the login credentials. The Query API supports two types of identity: local (or bucket) and admin. The format is an identity and password. You can specify credentials for multiple identities. If credentials are supplied in the request header, then HTTP Basic Authentication takes precedence and Example: |
Credentials array |
durability_level |
The level of durability for mutations produced by the request. If the request contains a Durability is also supported for non-transactional DML statements.
In this case, the If not specified, the default durability level is Values: |
String |
encoded_plan |
In Couchbase Server 6.5 and later, this parameter is ignored and has no effect. It is included for compatibility with previous versions of Couchbase Server. |
String |
encoding |
Desired character encoding for the query results. Only possible value is Default: |
String |
format |
Desired format for the query results. Values are case-insensitive. Values: |
String |
kvtimeout |
The approximate time to wait for a KV get operation before timing out.
This applies to statements within a transaction, and to non-transactional statements, whether If The value for this parameter is a string.
Its format includes an amount and a mandatory unit, e.g.
Specify a duration of Default: |
String |
max_parallelism |
Specifies the maximum parallelism for the query. The node-level In addition, the cluster-level To enable queries to run in parallel, you must specify the cluster-level The default value is the same as the number of partitions of the index selected for the query. Example: |
Integer (int32) |
memory_quota |
Specifies the maximum amount of memory the request may use, in MB. Specify This parameter enforces a ceiling on the memory used for the tracked documents required for processing a request. It does not take into account any other memory that might be used to process a request, such as the stack, the operators, or some intermediate values. Within a transaction, this setting enforces the memory quota for the transaction by tracking the delta table and the transaction log (approximately). The node-level In addition, the cluster-level Default: |
Integer (int32) |
metrics |
Specifies that metrics should be returned with query results. Default: |
Boolean |
namespace |
Specifies the namespace to use. Currently, only the Example: |
String |
numatrs |
Specifies the total number of active transaction records. Must be a positive integer. The node-level In addition, the cluster-level Default: |
Integer (int32) |
pipeline_batch |
Controls the number of items execution operators can batch for Fetch from the KV. The node-level In addition, the cluster-level Example: |
Integer (int32) |
pipeline_cap |
Maximum number of items each execution operator can buffer between various operators. The node-level In addition, the cluster-level Example: |
Integer (int32) |
prepared |
Required if The name of the prepared SQL++ statement to be executed. Refer to EXECUTE for examples. If both Example: |
String |
preserve_expiry |
Specifies whether documents should keep their current expiration setting when modified by a DML statement. If If Not supported for statements in a transaction. Default: |
Boolean |
pretty |
Specifies the query results returned in pretty format. The node-level Example: |
Boolean |
profile |
Specifies if there should be a profile section returned with the request results. The valid values are:
If The node-level Values: |
String |
query_context |
Specifies the namespace, bucket, and scope used to resolve partial keyspace references within the request. The query context may be a full path, containing namespace, bucket, and scope; or a relative path, containing just the bucket and scope.
Currently, only the Default: |
String |
readonly |
Controls whether a query can change a resulting recordset. If
When using GET requests, it's best to set Default: |
Boolean |
scan_cap |
Maximum buffered channel size between the indexer client and the query service for index scans. This parameter controls when to use scan backfill. Use The node-level In addition, the cluster-level Example: |
Integer (int32) |
scan_consistency |
Specifies the consistency guarantee or constraint for index scanning. The valid values are:
Values are case-insensitive. For multi-statement requests, the default behavior is RYOW within each request.
If you want to disable RYOW within a request, add a separate If the request contains a Values: |
String |
scan_vector |
Required if Specify the lower bound vector timestamp for one keyspace when using Scan vectors are built of two-element [
Scan vectors have two forms:
Note that For queries referencing multiple keyspaces, use Example: |
Object |
scan_vectors |
Required if A map from keyspace names to scan vectors.
See The scan vectors can be Full or Sparse. |
Object |
scan_wait |
Can be supplied with Specifies the maximum time the client is willing to wait for an index to catch up to the vector timestamp in the request. Specifies how much time the client is willing to wait for the indexer to satisfy the required Its format includes an amount and a mandatory unit, e.g.
Specify Default: |
String (duration) |
signature |
Include a header for the results schema in the response. Default: |
Boolean |
sort_projection |
If If Default: |
Boolean |
statement |
Required if Any valid SQL++ statement for a POST request, or a read-only SQL++ statement (SELECT, EXPLAIN) for a GET request. If both When specifying the request parameters as form data, the statement may not contain an unescaped semicolon ( This restriction does not apply when specifying the request parameters in JSON format. Example: |
String |
timeout |
Maximum time to spend on the request before timing out. The value for this parameter is a string.
Its format includes an amount and a mandatory unit, e.g.
Specify a duration of If tximplicit or txid is set, this parameter is ignored. The request inherits the remaining time of the transaction as timeout. The node-level In addition, the cluster-level Example: |
String (duration) |
txdata |
Transaction data. For internal use only. |
Object |
txid |
Required for statements within a transaction. Transaction ID. Specifies the transaction to which a statement belongs. For use with DML statements within a transaction, rollbacks, and commits. The transaction ID should be the same as the transaction ID generated by the Example: |
UUID (UUID) |
tximplicit |
Specifies that a DML statement is a singleton transaction. When this parameter is true, the Query service starts a transaction and executes the statement. If execution is successful, the Query service commits the transaction; otherwise the transaction is rolled back. The statement may not be part of an ongoing transaction.
If the txid request-level parameter is set, the Default: |
Boolean |
txstmtnum |
Transaction statement number. The transaction statement number must be a positive integer, and must be higher than any previous transaction statement numbers in the transaction. If the transaction statement number is lower than the transaction statement number for any previous statement, an error is generated. Example: |
Integer (int32) |
txtimeout |
Maximum time to spend on a transaction before timing out.
Only applies to Within a transaction, the request-level timeout parameter is ignored.
The transaction timeout clock starts when the The value for this parameter is a string.
Its format includes an amount and a mandatory unit, e.g.
Specify a duration of The node-level In addition, the cluster-level The default is Example: |
String (duration) |
use_cbo |
Specifies whether the cost-based optimizer is enabled. The node-level In addition, the cluster-level Example: |
Boolean |
use_fts |
Specifies that the query should use a full-text index. If the query contains a If the query does not contain a Refer to Flex Indexes for more information. Default: |
Boolean |
use_replica |
Specifies whether a query can fetch data from a replica vBucket if active vBuckets are inaccessible. The possible values are:
The node-level In addition, the cluster-level Do not enable read from replica when you require consistent results. Only SELECT queries that are not within a transaction can read from replica. Reading from replica is only possible if the cluster uses Couchbase Server 7.6.0 or later. Note that KV range scans cannot currently be started on a replica vBucket. If a query uses sequential scan and a data node becomes unavailable, the query might return an error, even if read from replica is enabled for the request. Values: |
String |
additional |
Supplies the value for a named parameter in the statement. Applicable if the statement or prepared statement contains 1 or more named parameters. The name of this property consists of two parts:
The value of the named parameter can be any JSON value. Refer to Named Parameters and Positional Parameters for details. |
Any Type |
Credentials
| Property | Schema | |
|---|---|---|
user |
An identity for authentication. Note that bucket names may be prefixed with Example: |
String |
pass |
A password for authentication. Example: |
String |
Transactional Scan Consistency
If the request contains a BEGIN TRANSACTION statement, or a DML statement with the tximplicit parameter set to true, then the scan_consistency parameter sets the transactional scan consistency.
If you specify a transactional scan consistency of request_plus, statement_plus, or at_plus, or if you specify no transactional scan consistency, the transactional scan consistency is set to request_plus; otherwise, the transactional scan consistency is set as specified.
| Scan consistency at start of transaction | Transactional scan consistency |
|---|---|
Not set |
|
|
|
|
|
Any DML statements within the transaction that have no scan consistency set will inherit from the transactional scan consistency.
Individual DML statements within the transaction may override the transactional scan consistency.
If you specify a scan consistency of not_bounded for a statement within the transaction, the scan consistency for the statement is set as specified.
When you specify a scan consistency of request_plus, statement_plus, or at_plus for a statement within the transaction, the scan consistency for the statement is set to request_plus.
However, request_plus consistency is not supported for statements using a full-text index.
If any statement within the transaction uses a full-text index, by means of the SEARCH function or the Flex Index feature, the scan consistency is set to not_bounded for the duration of the full-text search.
| Scan consistency for statement within transaction | Inherited scan consistency |
|---|---|
Not set |
Transactional scan consistency |
|
|
|
|
Named Parameters and Positional Parameters
You can add placeholder parameters to a statement, so that you can safely supply variable values when you run the statement. A placeholder parameter may be a named parameter or a positional parameter.
-
To add a named parameter to a query, enter a dollar sign
$or an at sign@followed by the parameter name. -
To add a positional parameter to a query, enter a dollar sign
$or an at sign@followed by the number of the parameter, or enter a question mark?.
To run a query containing placeholder parameters, you must supply values for the parameters.
-
You can use additional request-level parameters to supply the values for named parameters. The name of this property is a dollar sign
$or an at sign@followed by the parameter name. -
The args request-level parameter enables you to supply a list of values for positional parameters.
You can supply the values for placeholder parameters using any of the methods used to specify request-level parameters.
Examples
To try the examples in this section, set the query context to the inventory scope in the travel sample dataset.
For more information, see Query Context.
-
Web Console
-
Command Line
-
REST API
The following query uses named parameter placeholders. The parameter values are supplied using the Run-Time Preferences window.
name |
|
value |
|
name |
|
value |
|
SELECT COUNT(*) FROM airport
WHERE country = $country AND geo.alt > @altitude;The named parameters and named parameter placeholders in this example use a mixture of @ and $ symbol prefixes.
You can use either of these symbols as preferred.
The following query uses named parameter placeholders. The parameter values are supplied using the cbq shell.
\SET -@country "France";
\SET -$altitude 500;
SELECT COUNT(*) FROM airport
WHERE country = $country AND geo.alt > @altitude;The named parameters and named parameter placeholders in this example use a mixture of @ and $ symbol prefixes.
You can use either of these symbols as preferred.
The following query uses named parameter placeholders. The parameter values are supplied using the Query Service REST API.
curl -v $BASE_URL/query/service \
-d 'statement=SELECT COUNT(*) FROM airport
WHERE country = $country AND geo.alt > @altitude
& query_context=travel-sample.inventory
& $country="France" & $altitude=500' \
-u $USER:$PASSWORDThe named parameters and named parameter placeholders in this example use a mixture of @ and $ symbol prefixes.
You can use either of these symbols as preferred.
-
Web Console
-
Command Line
-
REST API
The following query uses numbered positional parameter placeholders. The parameter values are supplied using the Run-Time Preferences window.
$1 |
|
$2 |
|
SELECT COUNT(*) FROM airport
WHERE country = $1 AND geo.alt > @2;In this case, the first positional parameter value is used for the placeholder numbered $1, the second positional parameter value is used for the placeholder numbered @2, and so on.
The numbered positional parameter placeholders in this example use a mixture of @ and $ symbol prefixes.
You can use either of these symbols as preferred.
The following query uses numbered positional parameter placeholders. The parameter values are supplied using the cbq shell.
\SET -args ["France", 500];
SELECT COUNT(*) FROM airport
WHERE country = $1 AND geo.alt > @2;In this case, the first positional parameter value is used for the placeholder numbered $1, the second positional parameter value is used for the placeholder numbered @2, and so on.
The numbered positional parameter placeholders in this example use a mixture of @ and $ symbol prefixes.
You can use either of these symbols as preferred.
The following query uses numbered positional parameter placeholders. The parameter values are supplied using the Query Service REST API.
curl -v $BASE_URL/query/service \
-d 'statement=SELECT COUNT(*) FROM airport
WHERE country = $1 AND geo.alt > @2
& query_context=travel-sample.inventory
& args=["France", 500]' \
-u $USER:$PASSWORDIn this case, the first positional parameter value is used for the placeholder numbered $1, the second positional parameter value is used for the placeholder numbered @2, and so on.
The numbered positional parameter placeholders in this example use a mixture of @ and $ symbol prefixes.
You can use either of these symbols as preferred.
-
Web Console
-
Command Line
-
REST API
The following query uses unnumbered positional parameter placeholders. The parameter values are supplied using the Run-Time Preferences window.
$1 |
|
$2 |
|
SELECT COUNT(*) FROM airport
WHERE country = ? AND geo.alt > ?;In this case, the first positional parameter value is used for the first ? placeholder, the second positional parameter value is used for the second ? placeholder, and so on.
The following query uses unnumbered positional parameter placeholders. The parameter values are supplied using the cbq shell.
\SET -args ["France", 500];
SELECT COUNT(*) FROM airport
WHERE country = ? AND geo.alt > ?;In this case, the first positional parameter value is used for the first ? placeholder, the second positional parameter value is used for the second ? placeholder, and so on.
The following query uses unnumbered positional parameter placeholders. The parameter values are supplied using the Query Service REST API.
curl -v $BASE_URL/query/service \
-d 'statement=SELECT COUNT(*) FROM airport
WHERE country = ? AND geo.alt > ?
& query_context=travel-sample.inventory
& args=["France", 500]' \
-u $USER:$PASSWORDIn this case, the first positional parameter value is used for the first ? placeholder, the second positional parameter value is used for the second ? placeholder, and so on.
For more details and examples, including examples using SDKs, see the Prepare Statements for Reuse guide.
Related Links
-
For more details about the SQL++ REST API, refer to Query Service REST API.
-
For more details about the Admin REST API, refer to Query Admin REST API.
-
For more details about the Query Settings API, refer to Query Settings REST API.
-
For more details about API content and settings, refer to REST API reference.