Databricks Support
- concept
This section describes how to use the Couchbase Spark Connector in the Databricks environment.
| To avoid classpath issues in the Databricks environment, the assembly jar needs to be used as a dependency. See the next section on how to load it properly. |
Compute Cluster Configuration
Most of the work required to connect to Couchbase from Databricks is done during cluster configuration and setup.
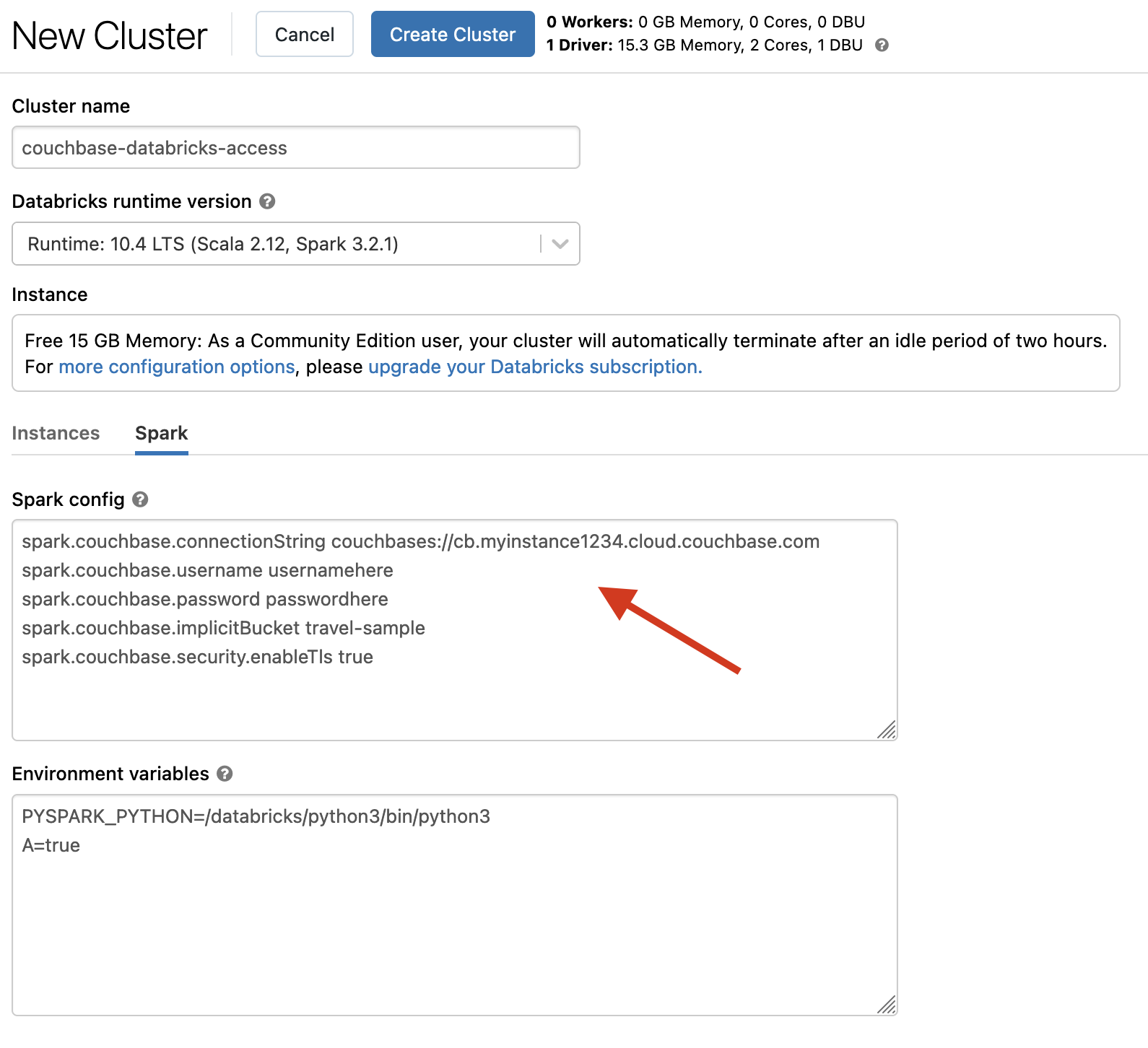
Before the cluster instance is started, Spark configuration properties need to be applied. The following properties illustrate how to connect to Couchbase Capella, please adjust the properties according to your needs.
spark.couchbase.connectionString couchbases://cb.myinstance1234.cloud.couchbase.com
spark.couchbase.username usernamehere
spark.couchbase.password passwordhere
spark.couchbase.implicitBucket travel-sample
spark.couchbase.security.enableTls trueThe following screenshot shows the configuration properties applied to a Spark 3.2.1 cluster Community Edition.
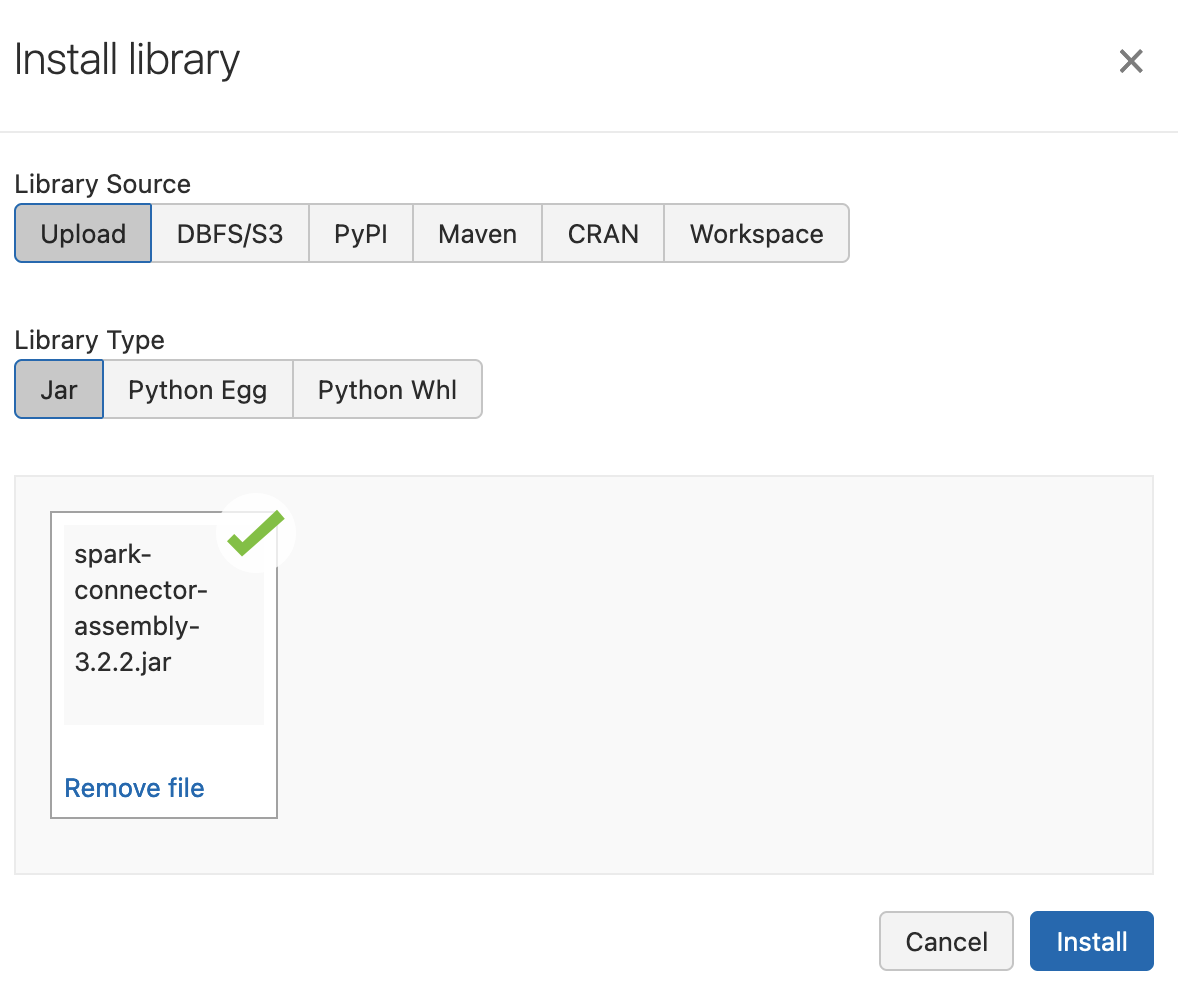
Once the cluster is started, the Couchbase Spark Connector needs to be attached as a dependency to the cluster. To avoid classpath issues in the environment, the assembly jar must be used (as opposed to the regular jar with transitive dependencies).
On the Download and API Reference page you can download the assembly jar for each version - please keep in mind that only 3.2.2 or later are supported.
Once the cluster is configured and running, it can be attached to your notebook. At this point the code in the individual notebooks is regular spark code, so please see the corresponding sections for more information.